Done
- EDA
한 픽셀에 여러 label이 있는지 확인했다.
그러한 경우가 있었지만 512x512 픽셀 중 그러한 경우는 무시할 정도로 적었다.
다행히 모든 픽셀은 하나의 label을 가지고 있고 이를 예측하면 될 것 같다. - U-Net 구현
원래는 DeepLab V1을 구현하려고 했는데 오늘 수업에서 U-Net을 배워서 이를 구현했다.
backbone model로 VGG16-BN을 사용했다.
현재 학습 중이다. - DeconvNet
어제 DeconvNet 구현 중 문제점을 발견했고 오늘 학습하여 제출했다.
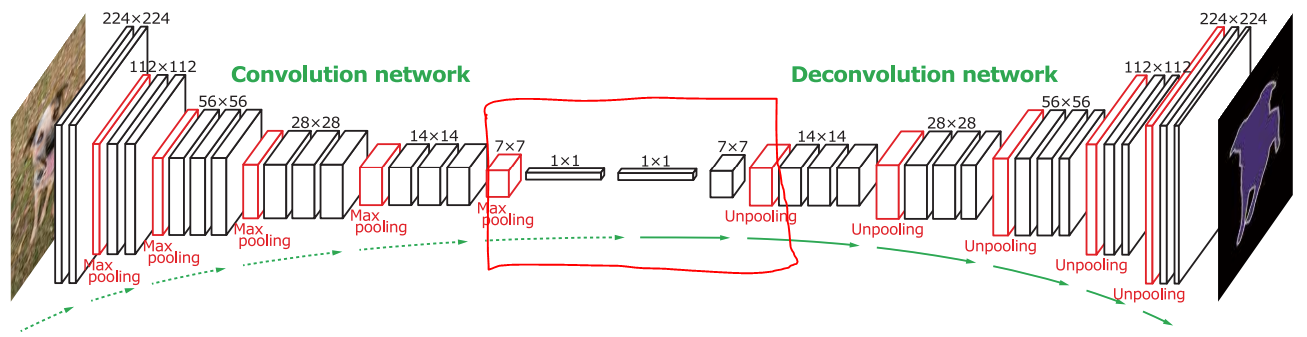 1
1
위 이미지에서 붉은색 박스를 두가지 버전으로 만들고 나머지는 동일하게 학습했다. - V1
7x7 conv+4096 -> 1x1 conv+4096 -> 7x7 deconv+512
conv옆 숫자는 출력 channel 수이다.
위 conv 모두 padding=0으로 하여 feature map의 사이즈를 줄이도록 했다.
학습 시간 약 2시간 - V2
7x7 conv+1024 -> 1x1 conv+1024 -> 7x7 deconv+512
V1과 다르게 channel 수를 줄였다.
학습 시간 약 1시간 50분
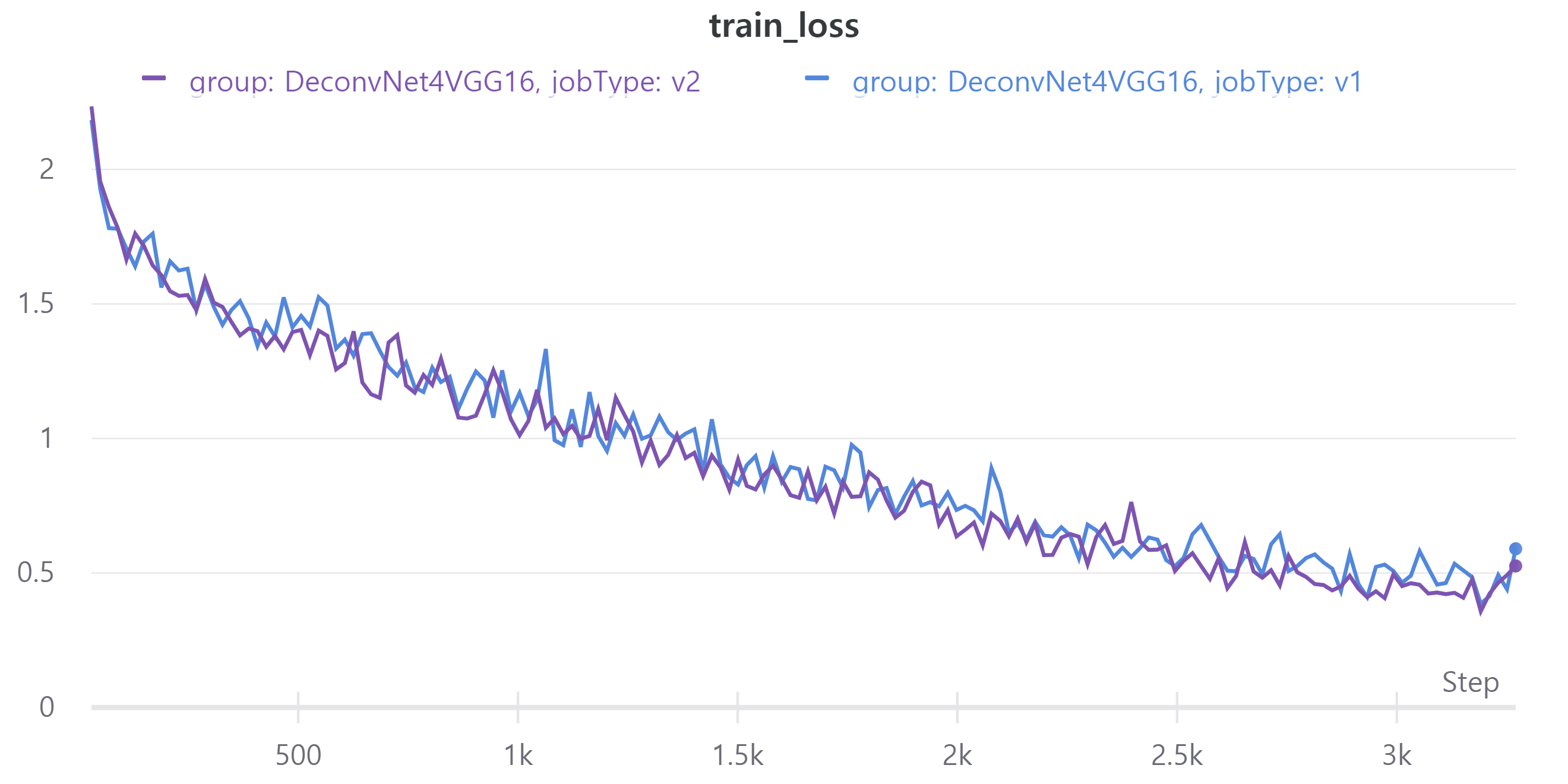
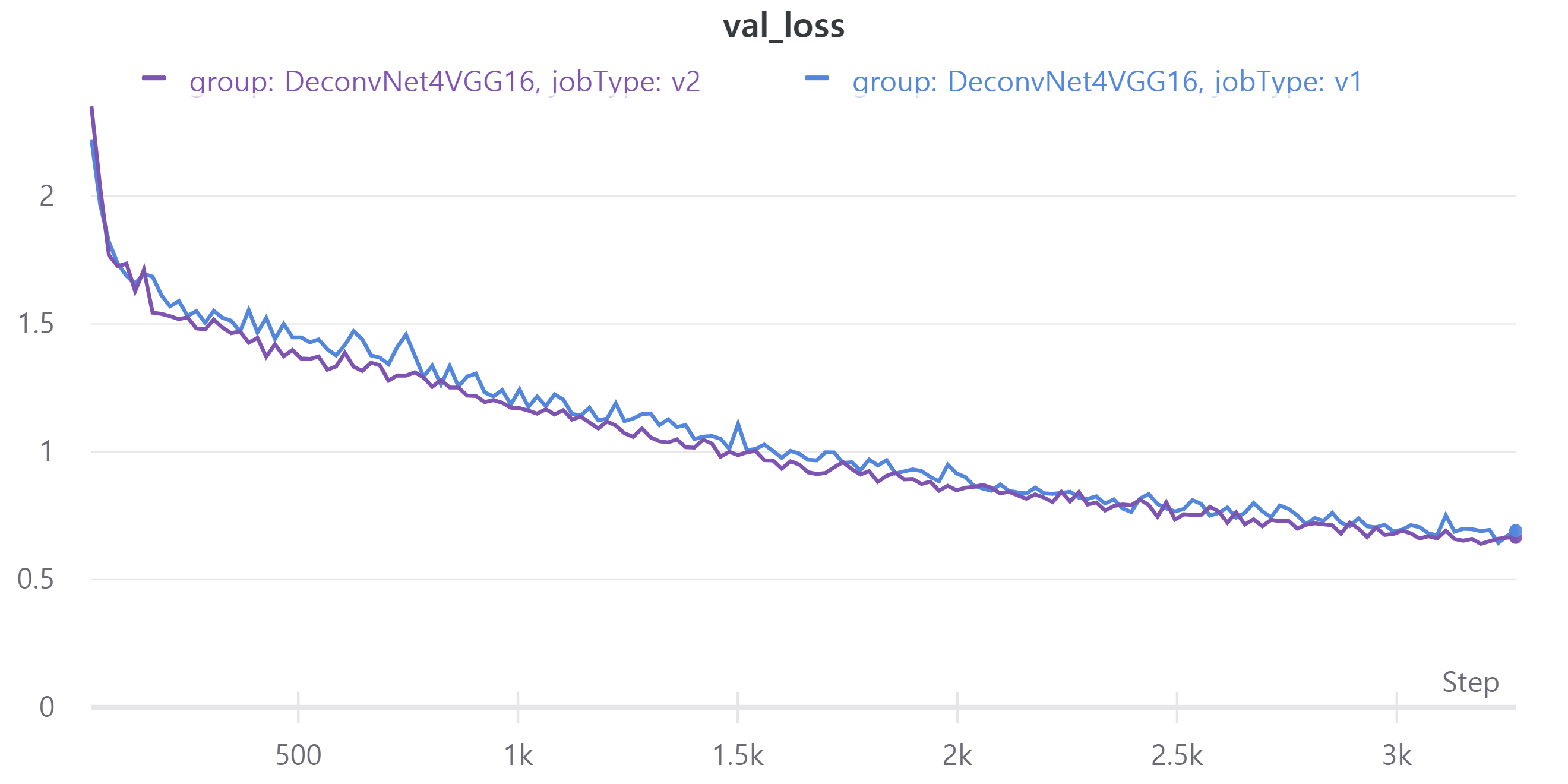
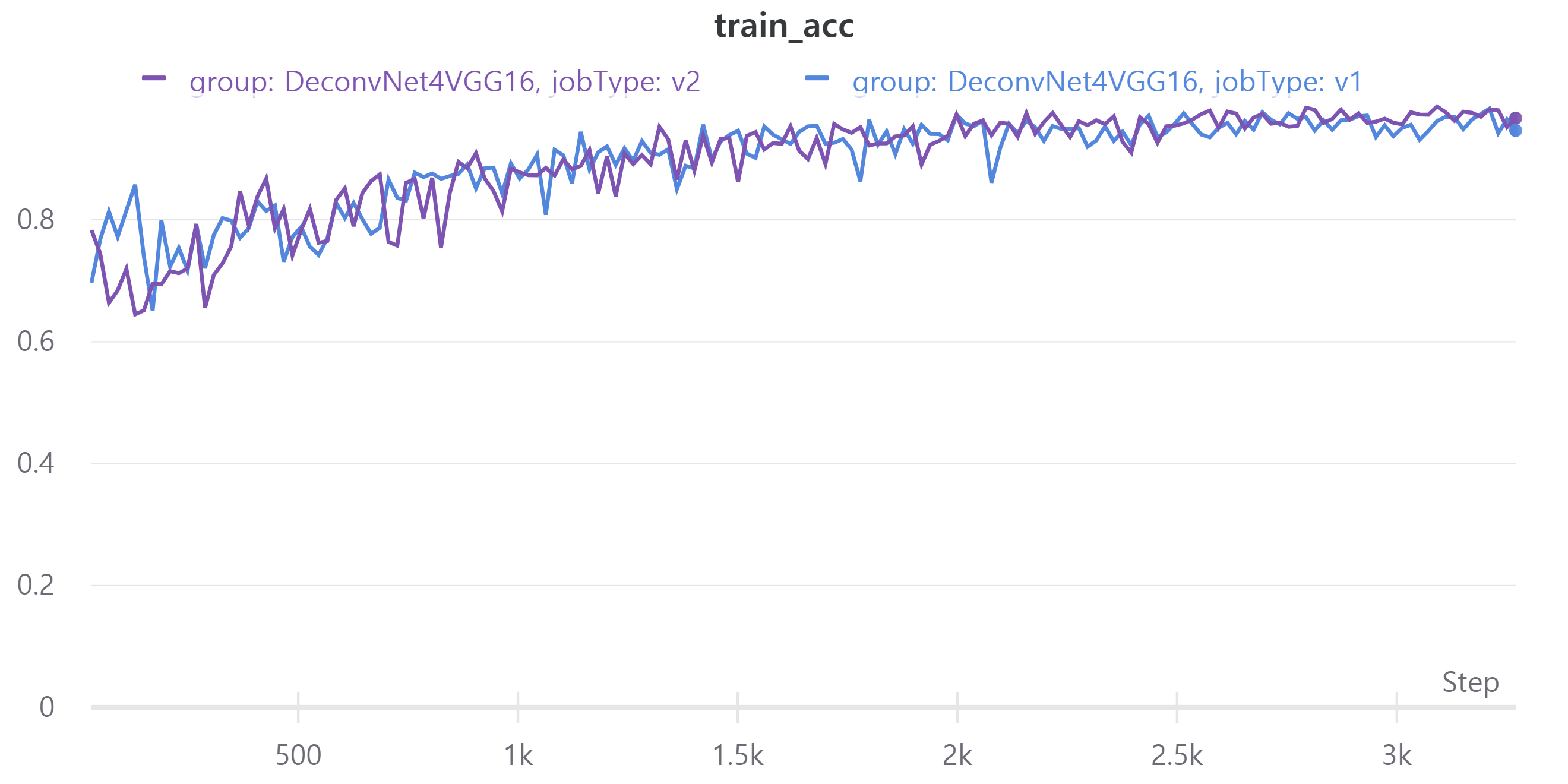
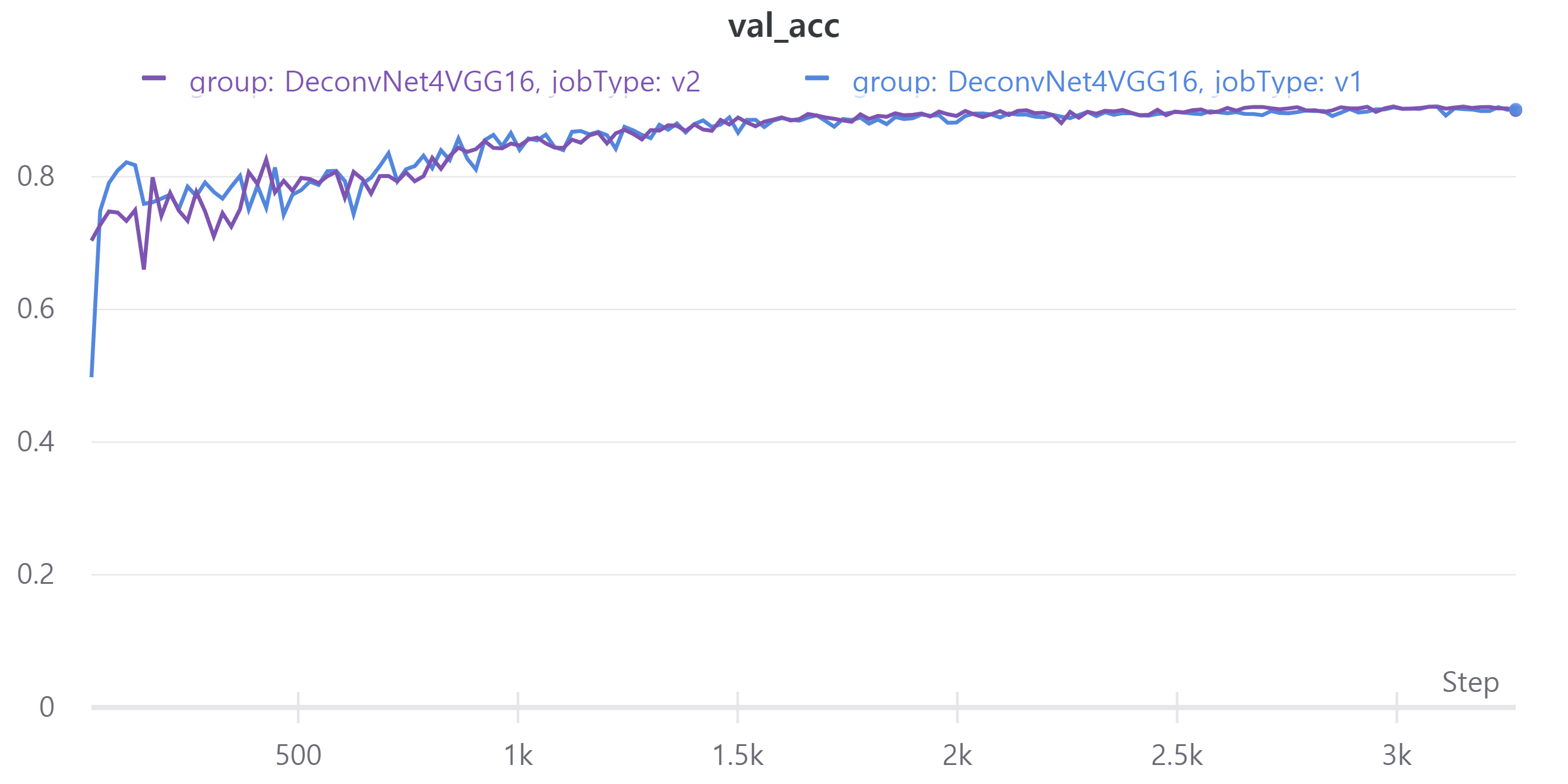
아래 그래프는 V1과 V2의 metric을 나타낸다.
- train - val loss
- train - val pixel-wise accuracy
- train - val mean IoU
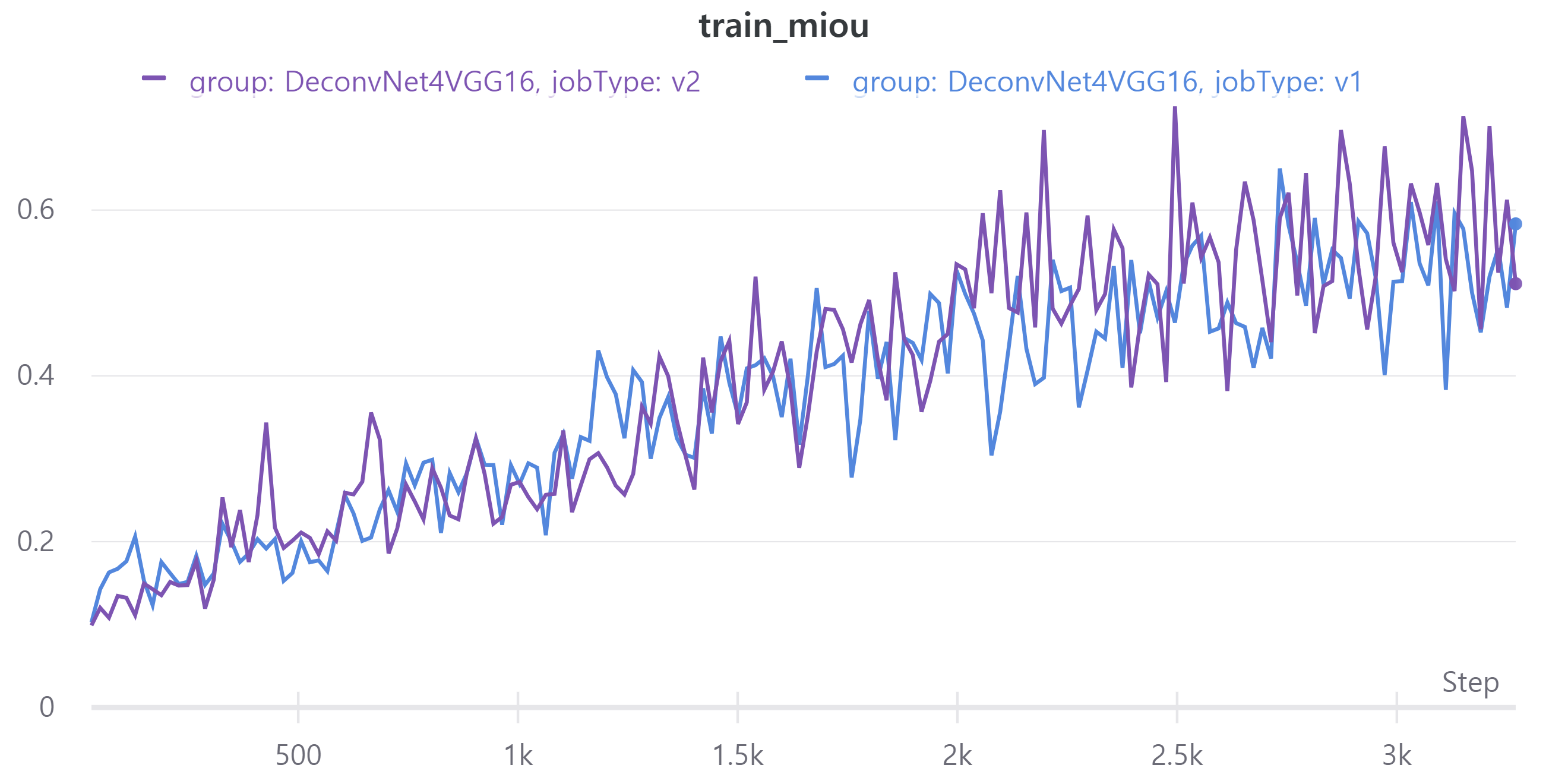
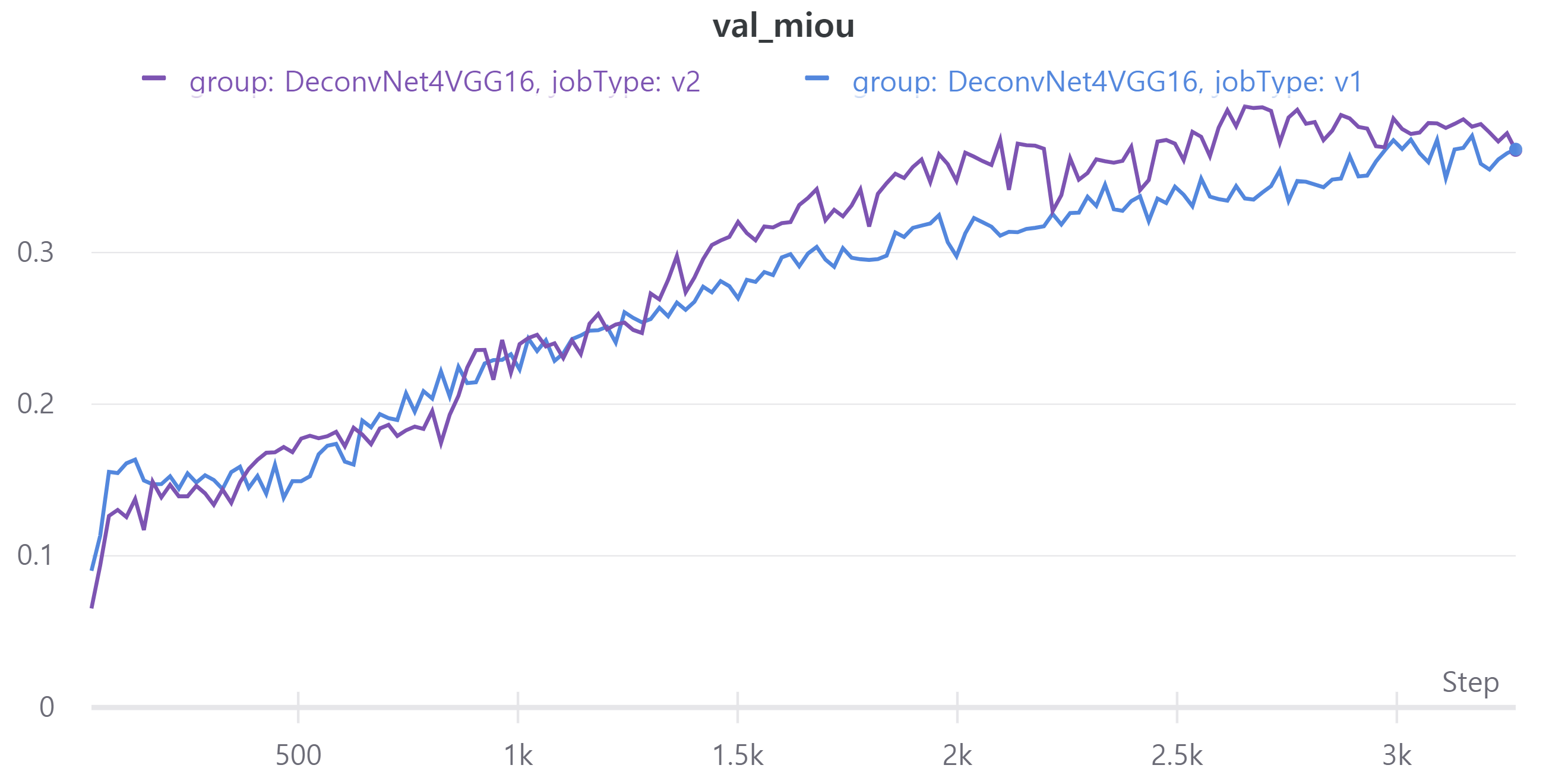
V1의 LB = 0.4546, V2의 LB = 0.4702
parameter 수를 줄였는데 V2의 성능이 더 좋아졌다.
다만 validation mean IoU가 LB랑 차이가 많다.
mean IoU 계산하는데 문제가 있는 것 같다.
To do
- DeepLab V1 구현
- 학습 정리 못한 강의들 정리하기
peer session
오늘 피어세션은 여기에 정리했다.