Done
- 현재 가장 성능이 좋은 모델인 DeconvNet4VGG16에 조금 변화를 줬다.
기존에는 learning rate를 고정으로 하고 adam optimizer를 사용했다.
scheduler를 사용하여 이 값을 변화하면 학습이 좀 더 빠르게 수렴하고 backbone model에 학습된 정보를 손실을 줄이기 위해 사용했다.
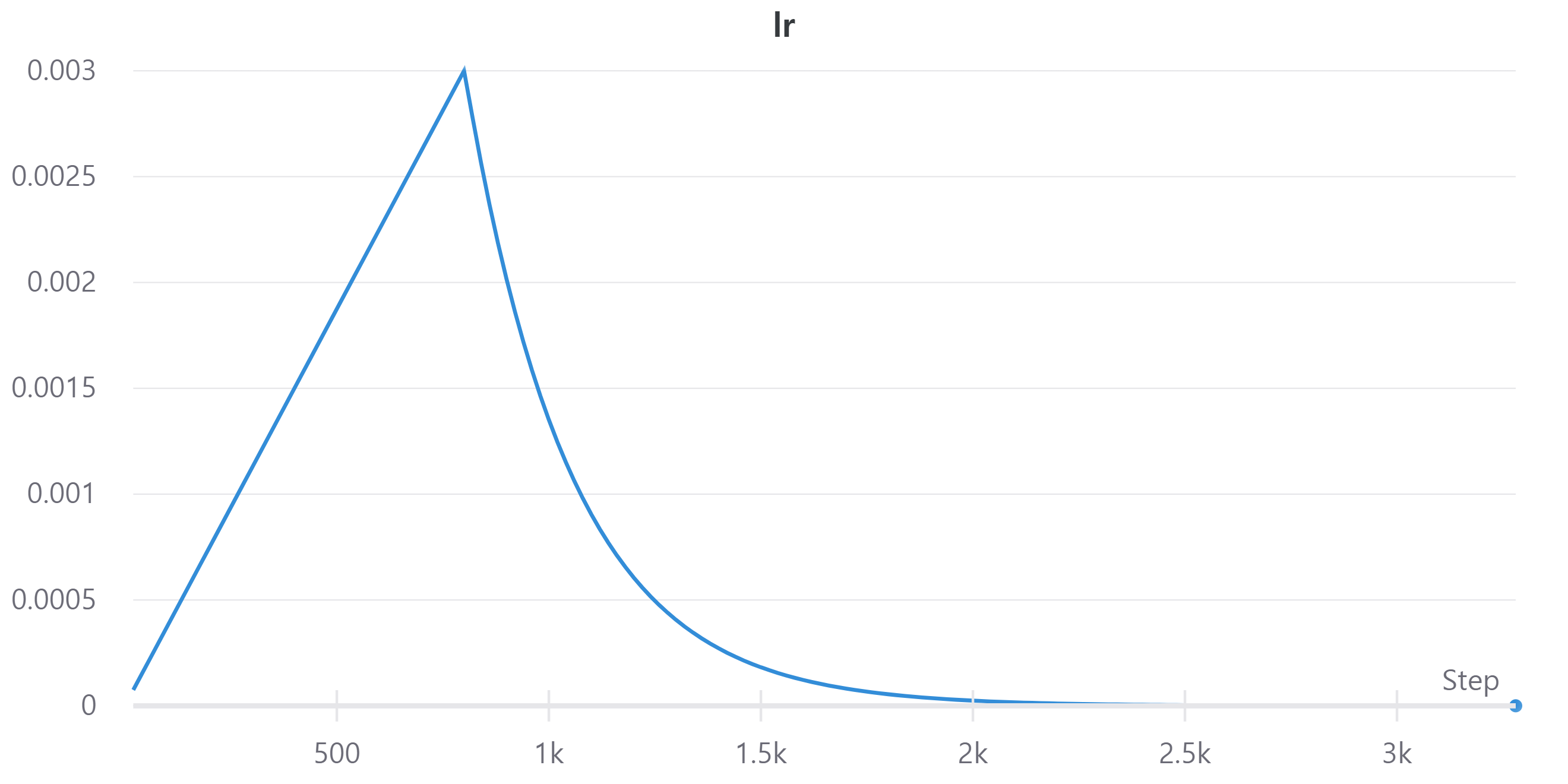
금요일 강의에서 소개한 gradual scheduler를 사용했다.
처음에는 0에서 시작하여 N번동안 증가하여 사전에 설정한 최고값에 도달하고 그 후 조금씩 감소한다.
다음 이미지는 learning rate의 변화를 나타낸다.
다음 이미지는 train, validation set에 대한 metric이다.
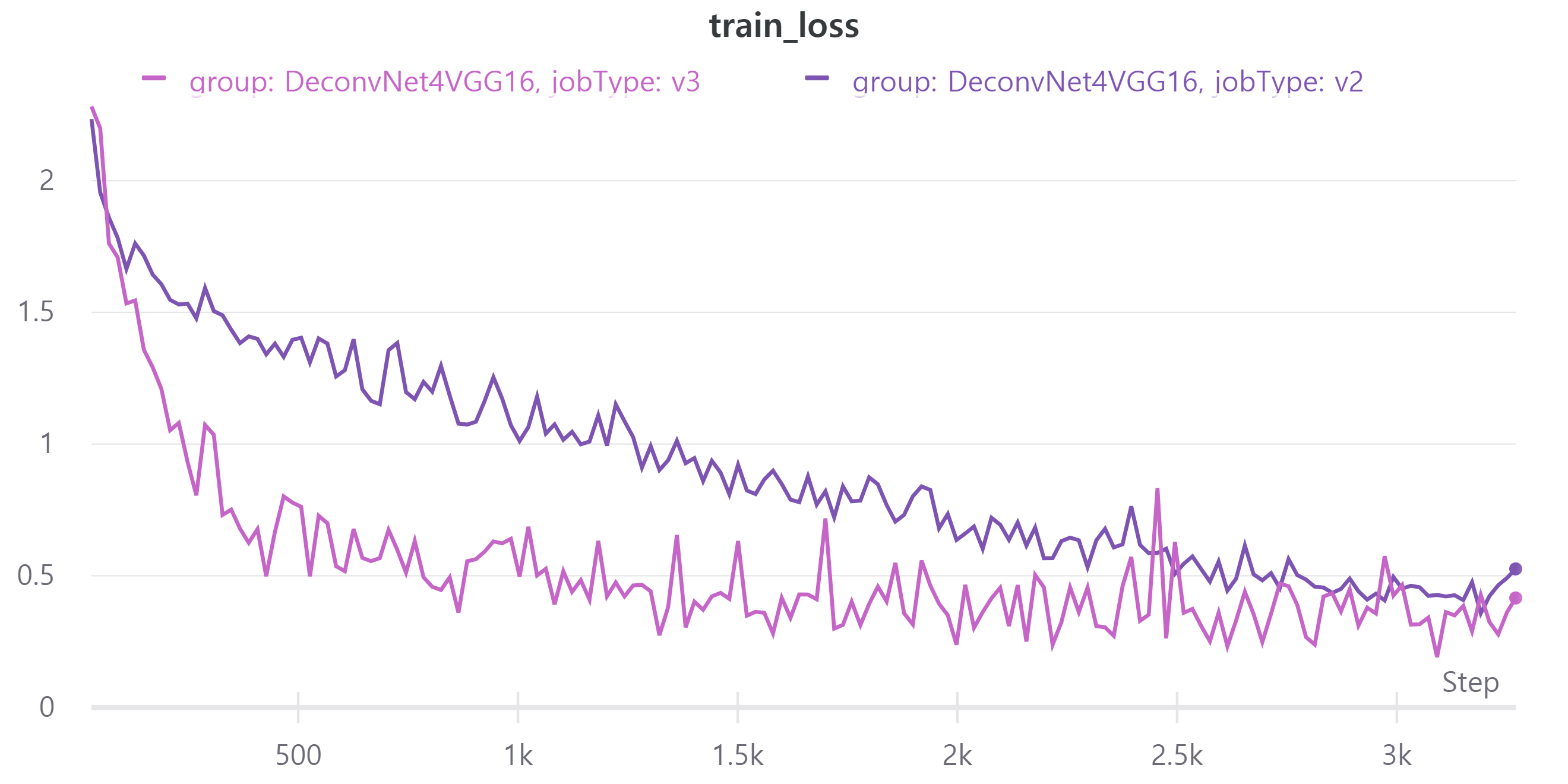
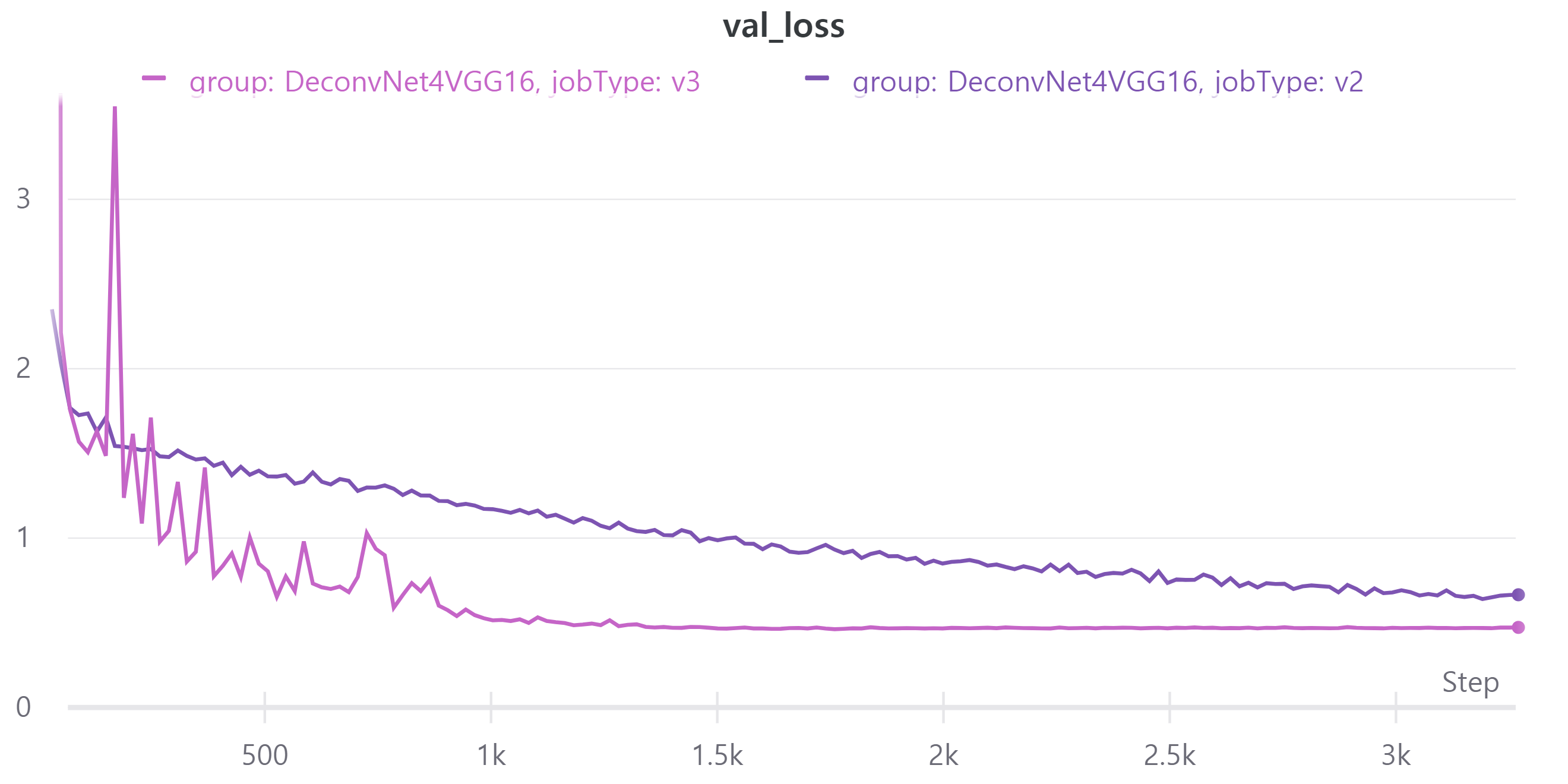
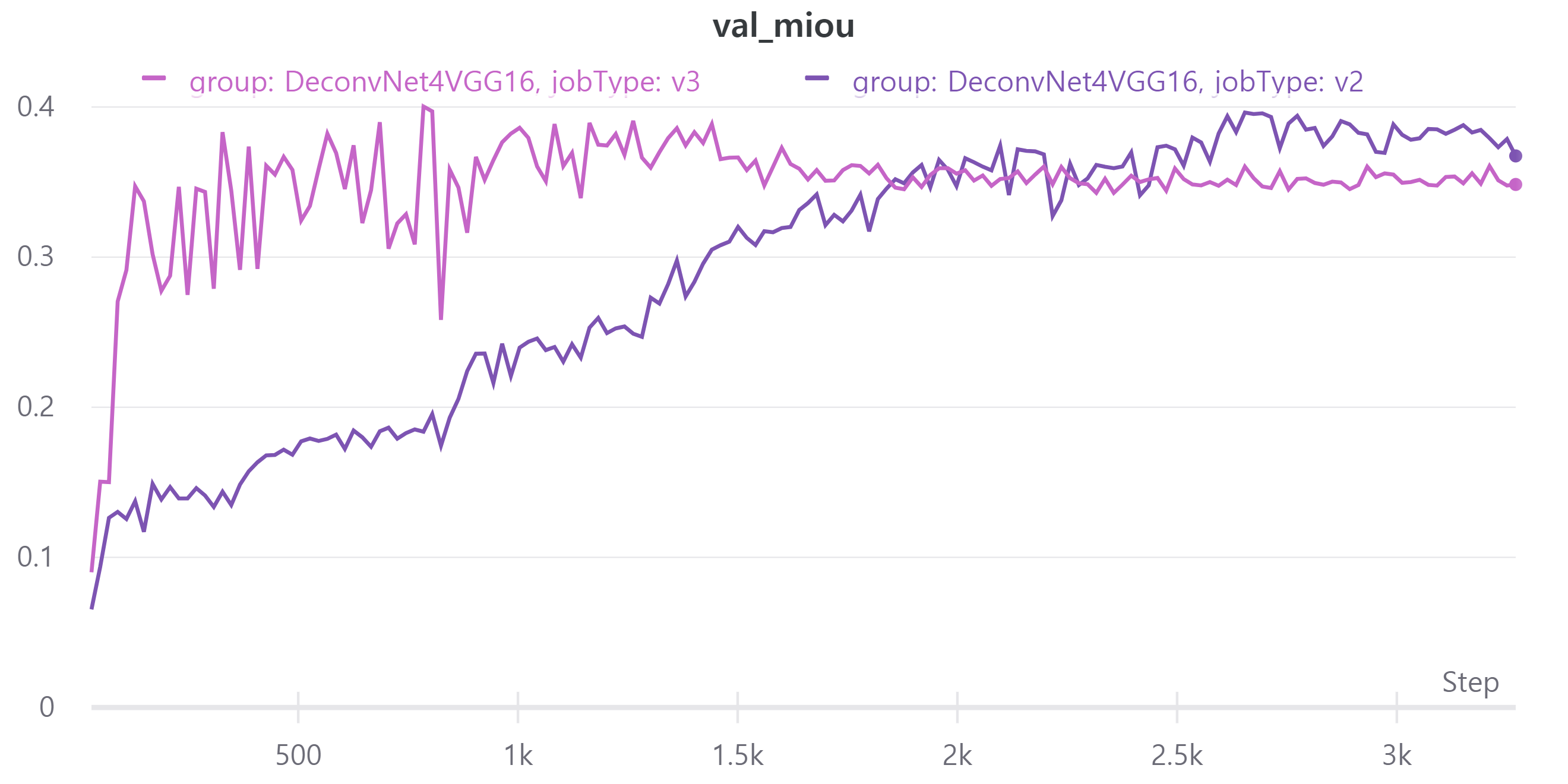
V3는 scheduler를 적용한 모델이고V2는 현재 가장 성능이 높은 모델이며 scheduler를 적용하지 않았다.- train, validation loss
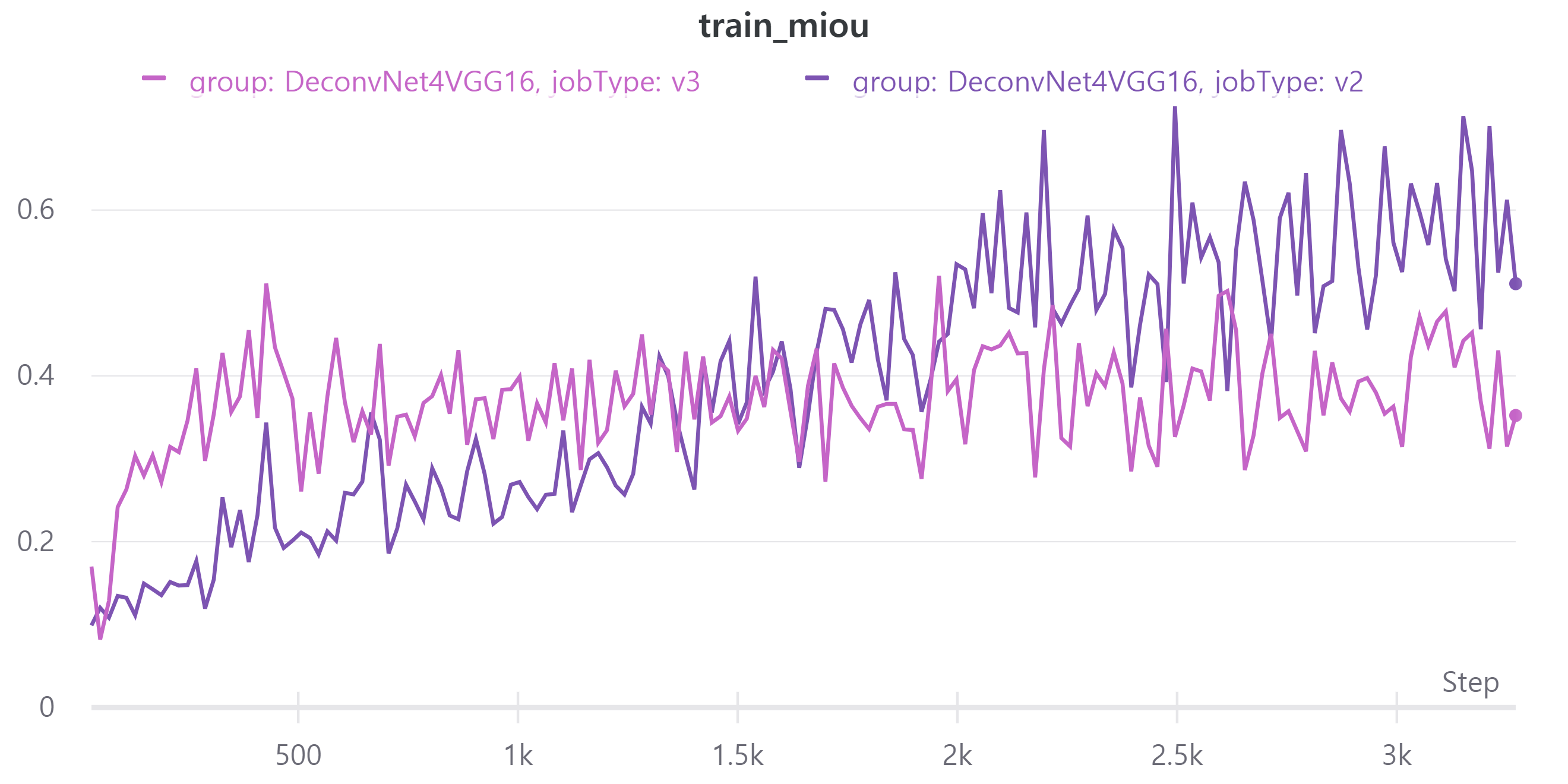
- train, validation mean IoU
- train, validation loss
V3의 public LB는 0.3893을 기록했다.
오히려 scheduler를 적용하니 성능이 떨어졌다.
learning rate가 증가하는 구간에서는 validation loss가 중간에 증가하는 경우가 있다.
줄어드는 구간에서는 일정한 모습을 보였다.
scheduler 정책을 수정해야할지 고민이다.
- Resize 적용
주어진 이미지의 크기는 512x512이고 평가할 때는 512x512의 예측 마스크를 256x256으로 줄여서 제출한다(제출 파일 크기가 너무 커서 줄였다고 한다).
그래서 학습 시 크기를 256x256으로 줄였다.
크기를 줄이면 이미지의 정보가 손실이 되지만 학습 속도가 많이 향상된다.
또한 batch size를 늘릴 수 있다.
backbone model로 VGG16을 사용하는데 batch Normalization를 포함하고 있다.
이는 batch size에 영향을 받으므로 이를 증가시키면 학습이 좀 더 안정적으로 될 것이라 생각했다.
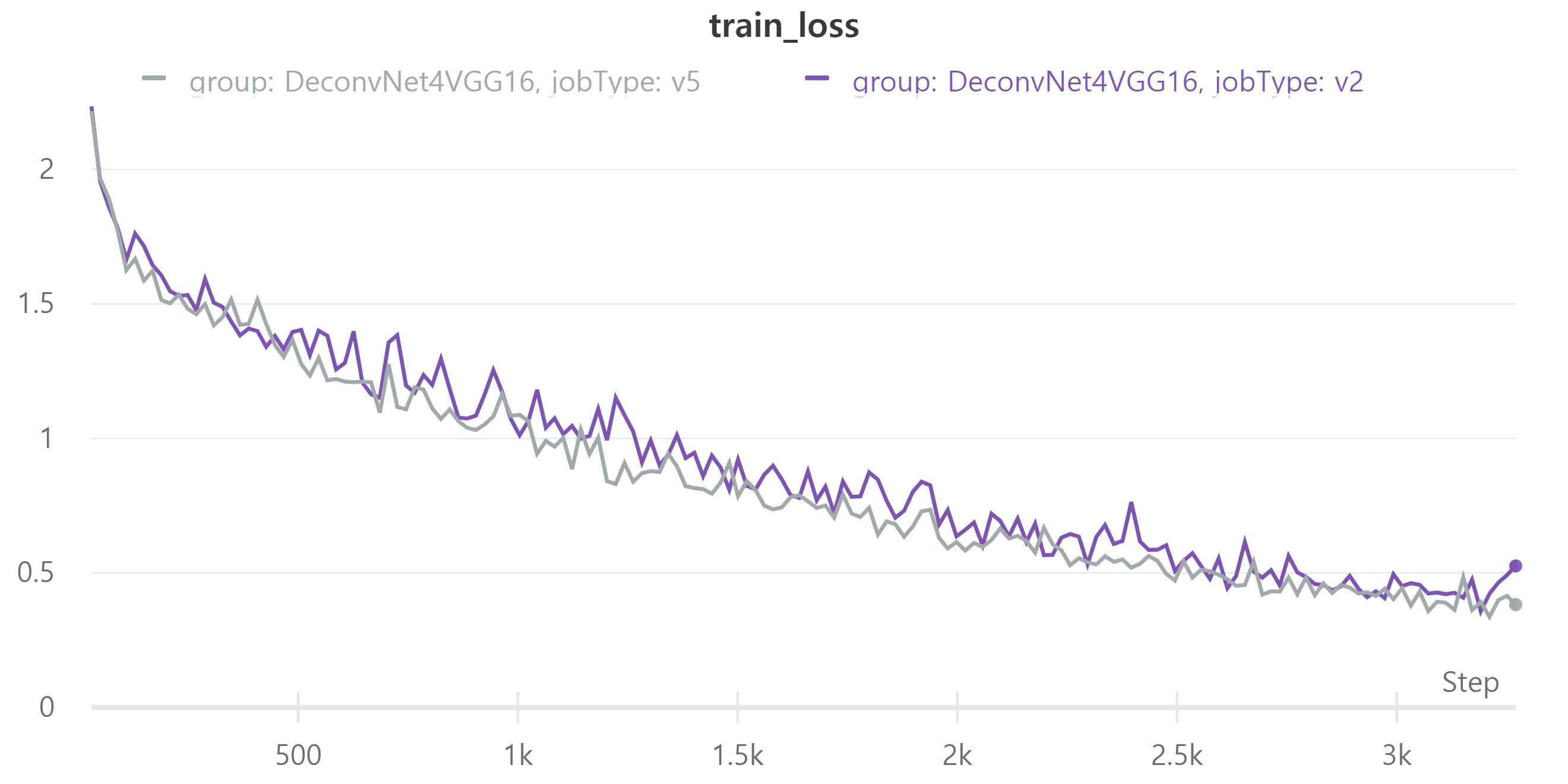
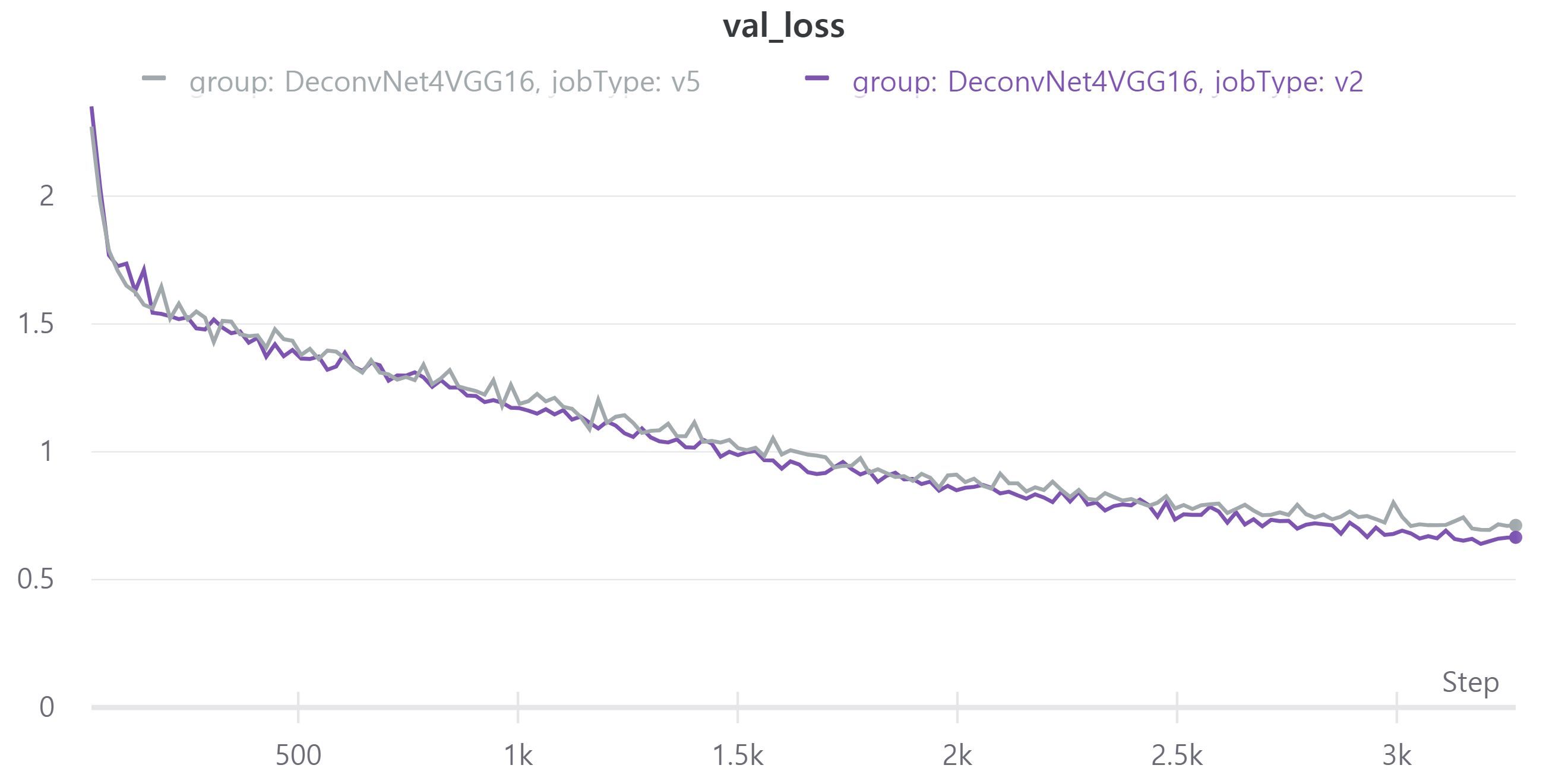
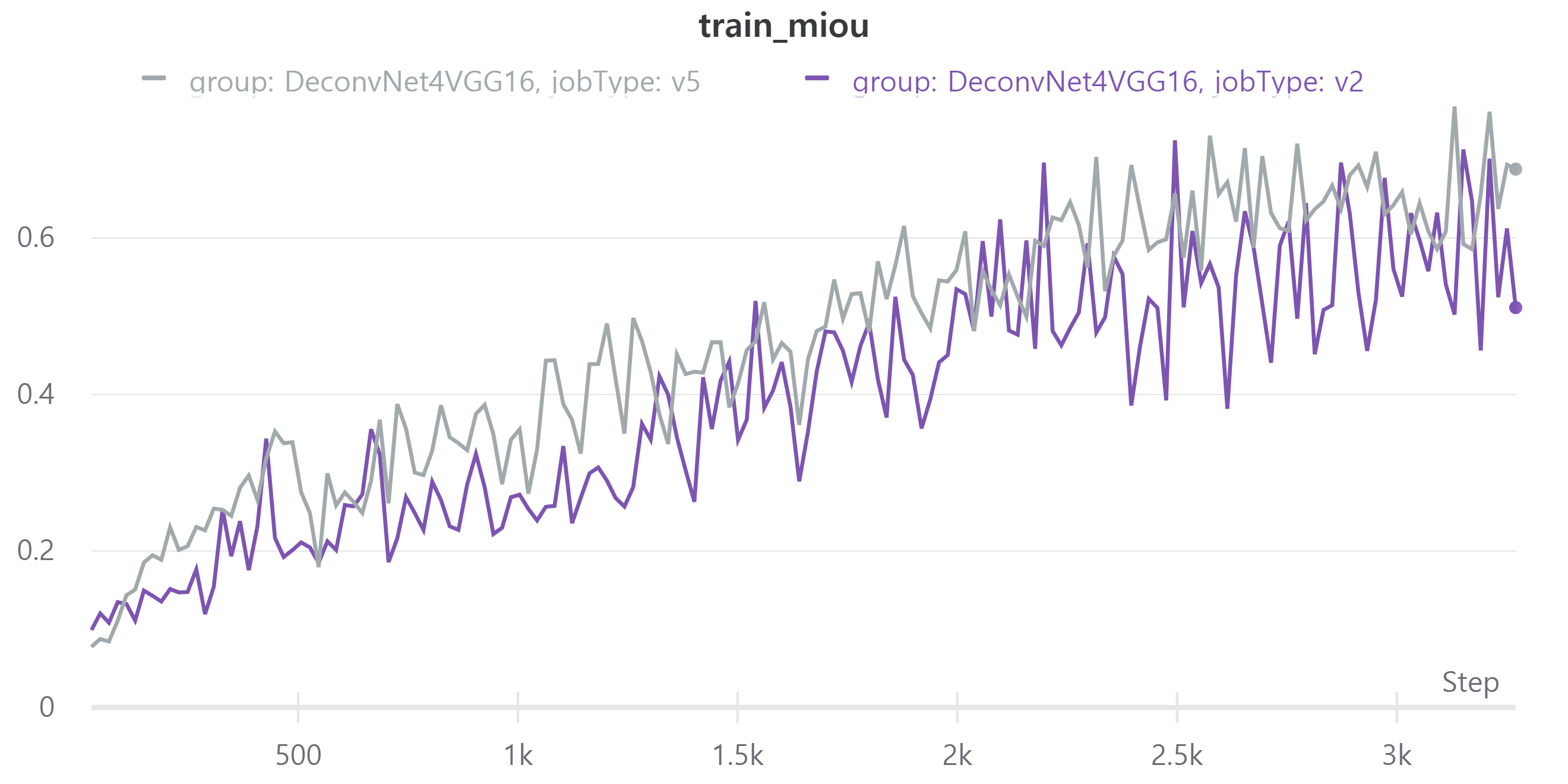
다음은 학습 결과이다.
V5는V2에서 256x256으로 크기를 줄였고 batch size를 32로, epoch을 40으로 했다.- train, validation loss
- train, validation mean IoU
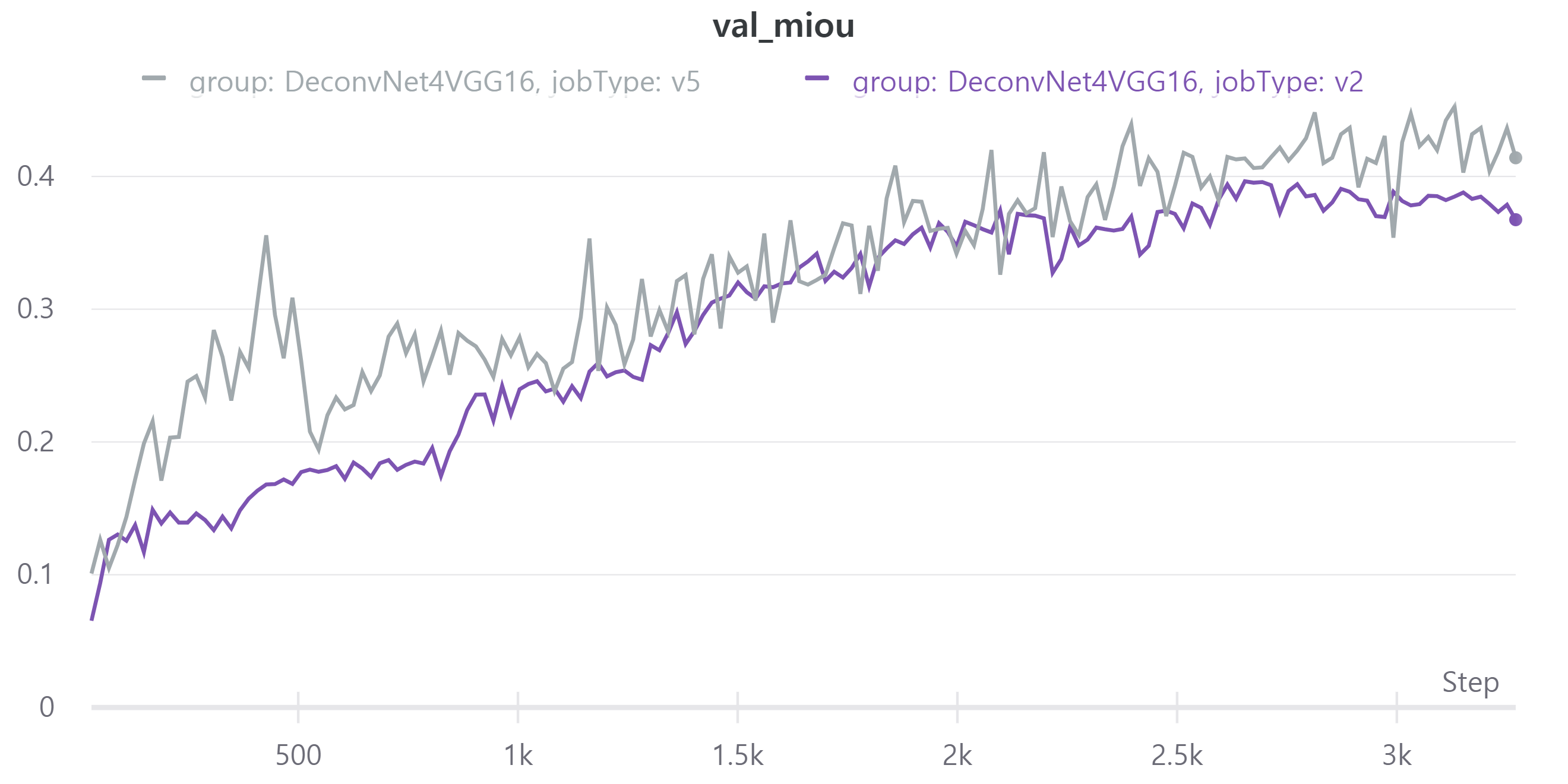
- train, validation loss
V5의 public LB는 0.4572로 V2의 public LB 0.4702에 비해 조금 낮다.
아무래도 이미지를 줄이다 보니 정보 손실로 인해 LB가 감소한 것 같다.
그렇지만 이는 다른 방법으로 보충할 수 있는 감소라 생각하여 앞으로 학습할 때 256x256으로 크기를 줄이기로 결정했다.
batch size를 64로, epoch을 100으로 늘려서 public LB 0.4811을 얻었다.
이 결과를 봤을 때 batch size를 증가하여 모델 안에 Batch Normalization에 의해 좀 더 학습이 잘 되었다고 판단했다.
또한 입력 이미지의 크기가 256x256으로 줄여서 계산량이 줄어들어 epoch을 늘린 것도 도움이 되었다고 생각한다.
위 validation loss와 mean IoU를 보면 계속 상승하는 추세를 보여서 epoch을 늘렸다.
-
CRF(conditional random field) DeepLab을 공부하다가 CRF에 관한 내용을 찾아보다가 이 글을 참고했다.
현재 semantic segmentation model들은 해상도를 줄여 이미지 내 객체들의 전반적인 특징을 얻는다.
원래 크기로 복원하는 과정에서 객체의 세밀한 정보를 잃게 된다.
이를 보완하는 후처리 기술이다.
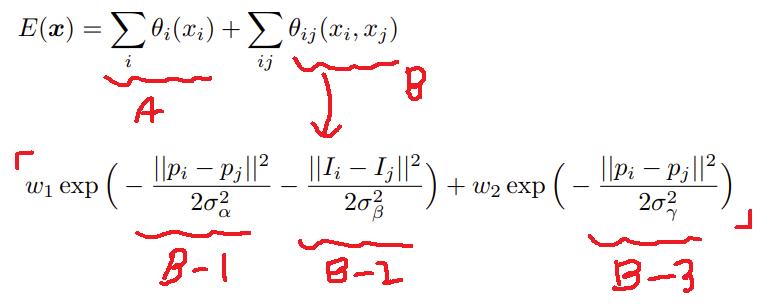
위 수식은 CRF에 대한 수식이다.
i, j는 픽셀을 의미한다.
A항과B항의 합으로 픽셀의 label을 결정한다.
A항은 model에 의해 얻은 픽셀별 probability이다.
B항은 두 픽셀에 대해 가우시안 커널을 의미한다.
B-1은 두 픽셀의 위치의 차이,B-2는 두 픽셀의 RGB 이미지 픽셀 값의 차이,B-3역시 픽셀의 위치 차이를 의미한다.
즉,B항의 값은 두 픽셀의 위치가 가깝고 RGB 값이 비슷하면 높은 값을 얻는다.
w는 가중치를 의미한다.
이를 현재 가장 성능이 좋은 모델에 적용하였고 public LB0.5341을 얻었다.
CRF 적용 전과 비교하여0.05향상 되었다.
앞으로 모든 모델들은 CRF를 적용할 것이다. -
DeepLabV1, V2
다음 이미지는 현재 best model인V5와DeepLabV1,DeepLabV2에 대한 metric이다.- train, validation loss
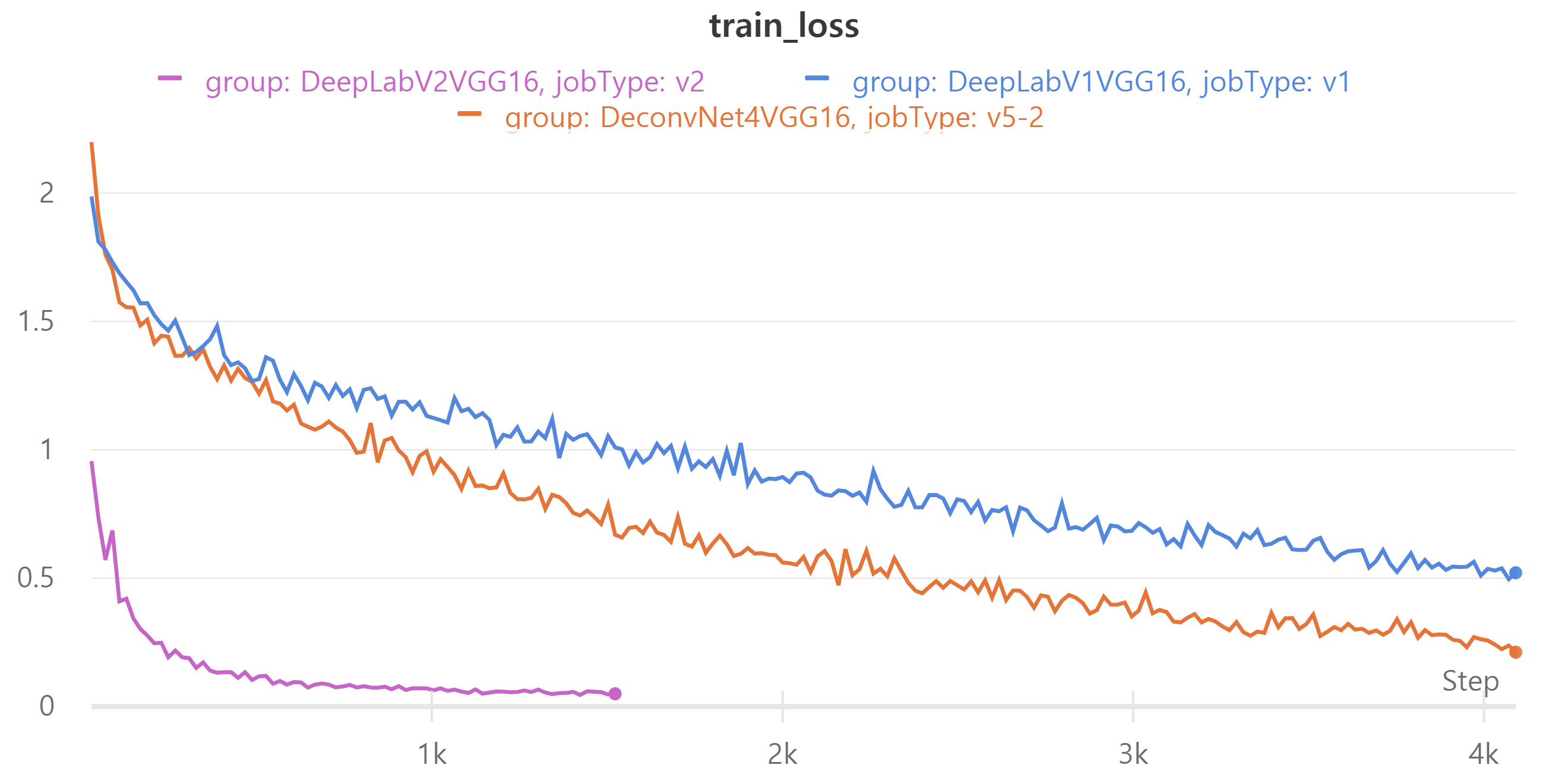
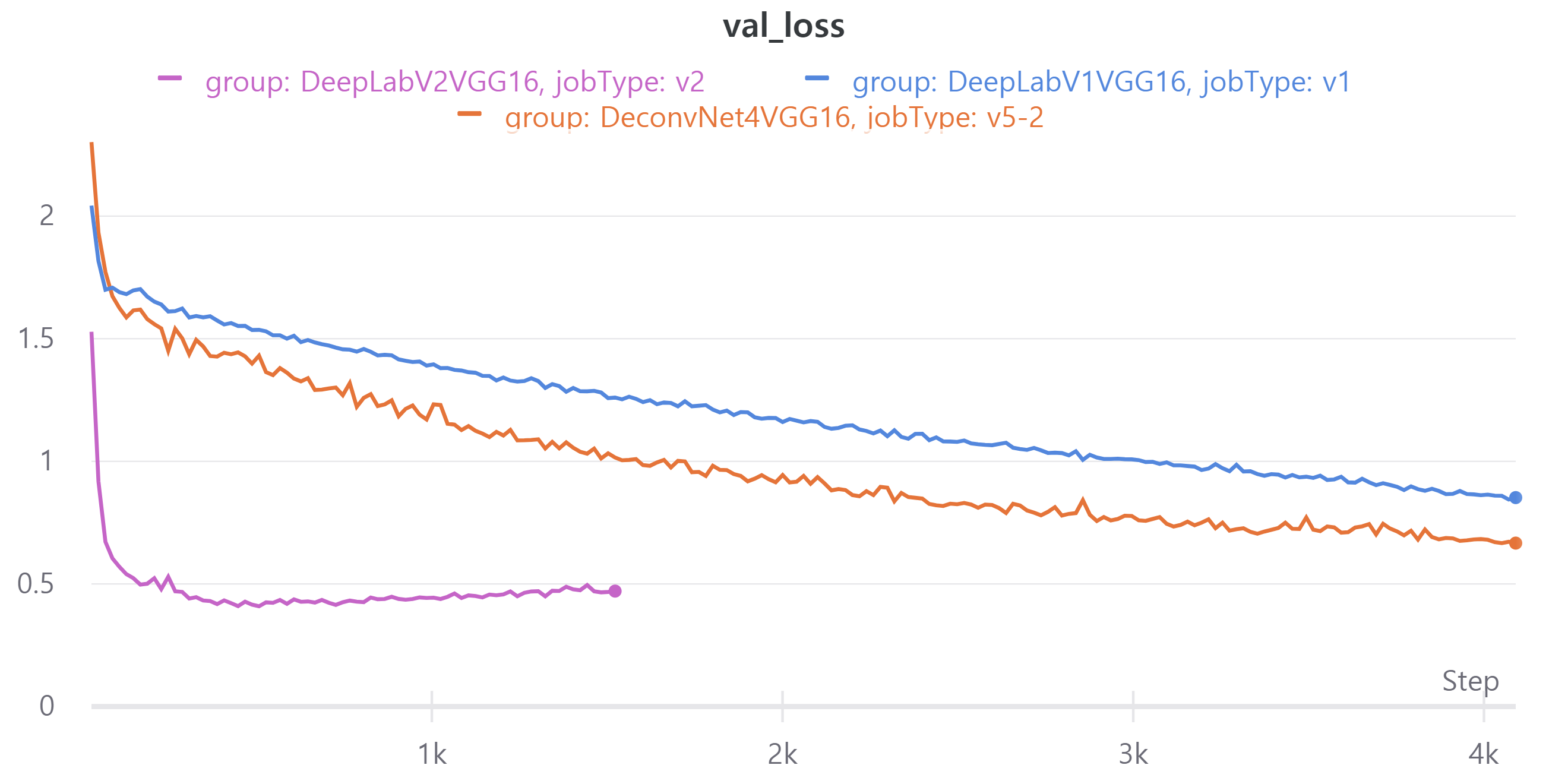
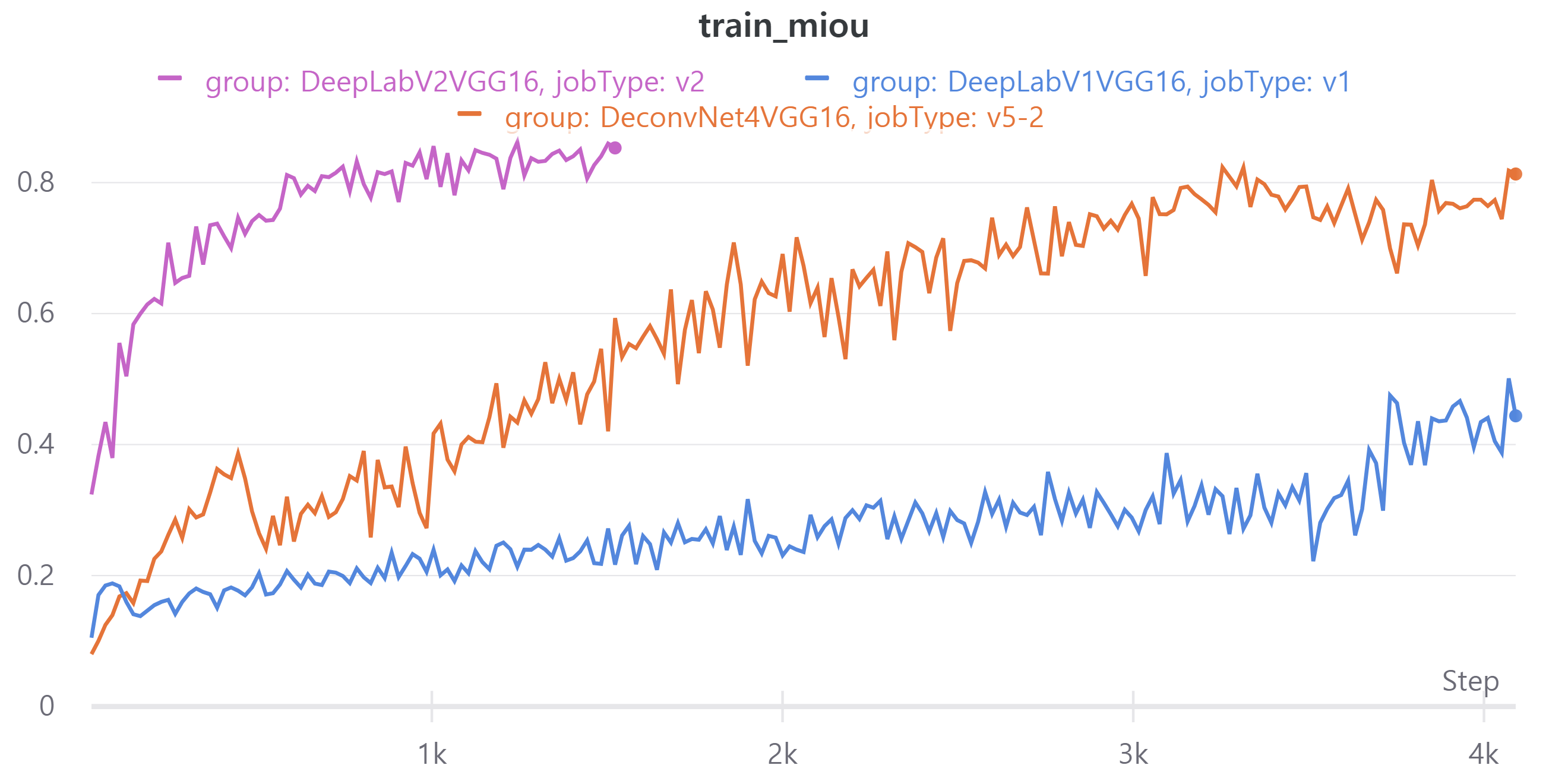
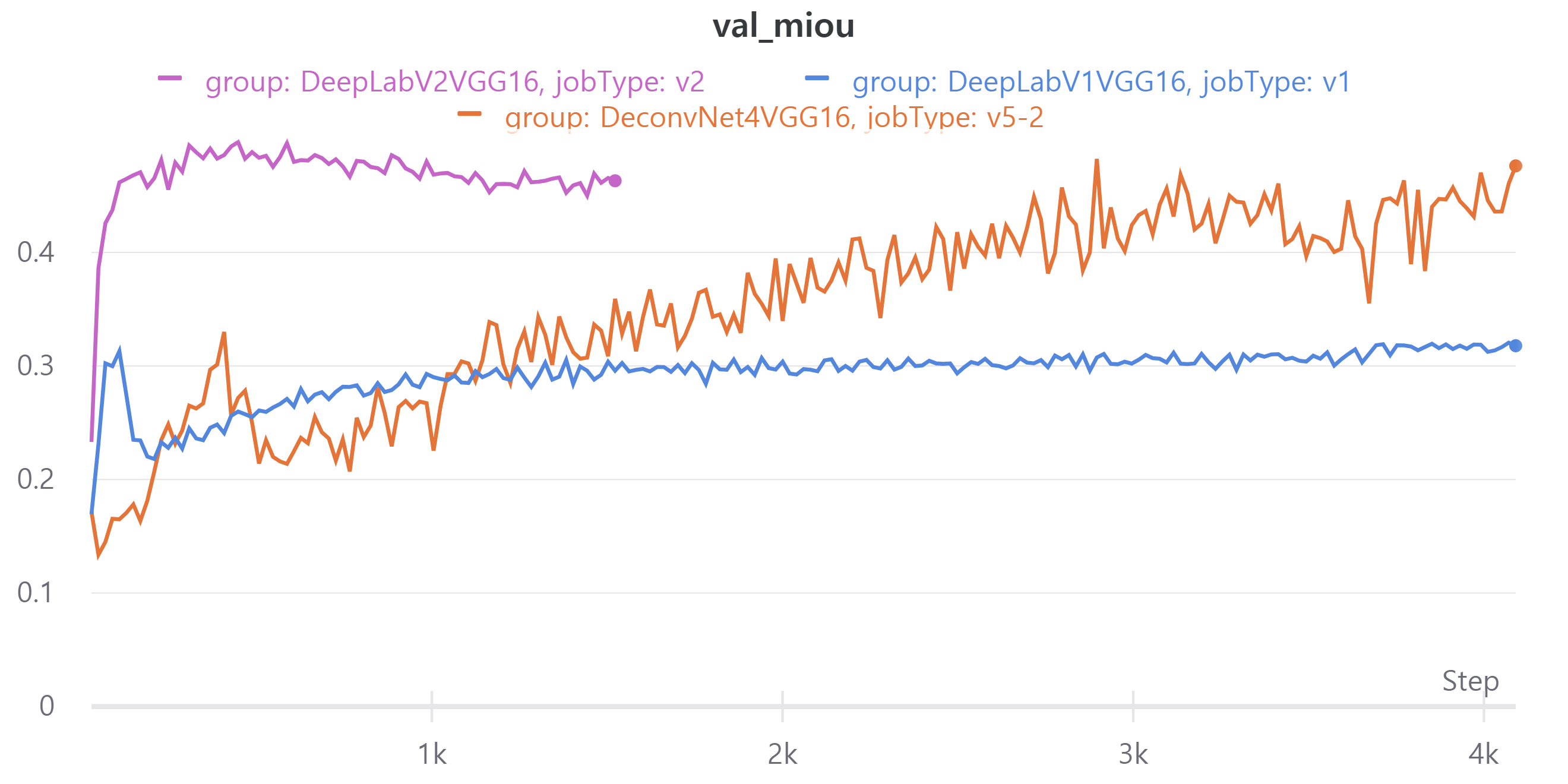
- train, validation loss
DeepLabV2의 epoch을 100으로 설정하였으나 더이상 validation loss가 감소하지 않아 도중에 중단했다.
DeepLabV1의 public LB는 0.4566, DeepLabV2의 public LB는 0.5527을 얻었다.
기존 모델들은 다양한 크기의 객체를 예측하는데 어려움을 겪었다.
DeepLab은 이를 개선한 모델이라 좋은 성능을 얻었다고 판단했다.
To do
- DeepLabV3 구현
retrospective
정말 빠르게 지나간 주말이었다.
DeepLab 논문을 읽는데 시간을 많이 보냈다.
논문이 정말 안 읽혀서 고생을 많이 했다.
특히 CRF를 공부하는데 많은 어려움을 겪었다.
사실 아직도 잘 모르겠다.
이 프로젝트를 하면서 기분이 좋았던 것은 구현한 것이 좋은 성능을 보였을 때이다.
성능이 좋지 않다면 구현이 잘못된 것이므로 원인을 찾느라 고생을 많이 했다.
문제를 파악하고 수정했을 때 원래 결과보다 좋게 나올 때 보람을 느꼈다.