이번 프로젝트는 약 한달동안 진행된다.
주제는 OCR(Optical Character Recognition)이다.
이미지를 읽어 문자로 변환하는 task이며 여기서는 수학 수식 이미지가 주어지고 이를 Latex로 변환하는 모델을 만드는 것이 목표이다.
예를 들어 이미지가 아래와 같이 주어진다면 a \cdot b = a ^ T b 로 변환하는 것이다.
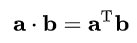
원래는 한 이미지에서 수식을 localization하고 Recognition하는 과정이 필요한데 localization이 포함되면 너무 어려워질 것 같아 미리 전처리를 해주었다고 한다.
EDA
주어진 데이터는 10만개이고 12,000개의 테스트 데이터가 있다.
이미지의 크기는 다양하며 수식에 대한 이미지이므로 좌우로 길고 위아래로 짧은 이미지이다.
높이가 가장 짧은 이미지의 크기는 20 x 72이다.
픽셀 수가 가장 많은 이미지는 3460 x 10640이다.
높이와 너비의 비율이 큰 경우가 있는데 높이에 비해 너비가 매우 긴 경우가 있다.
높이가 너비보다 긴 경우가 있는데 이는 아래와 같이 90도 혹은 -90도 회전한 모습이다.
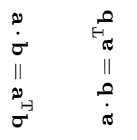
이 경우는 전체 학습 데이터 중 약 2천개 정도로 전체의 2%를 차지한다.
또한 180도 회전된 수식도 존재 했다.
또 다른 특징은 수식에 형광펜이나 볼드체 및 다양한 필체가 있다.
사람이 직접 쓴 수식과 컴퓨터로 출력한 수식도 존재한다.
10만개의 데이터 중 5만개는 손 글씨, 5만개는 인쇄된 이미지이다.
다음 이미지는 수식 길이에 대한 히스토그램과 요약 통계이다.
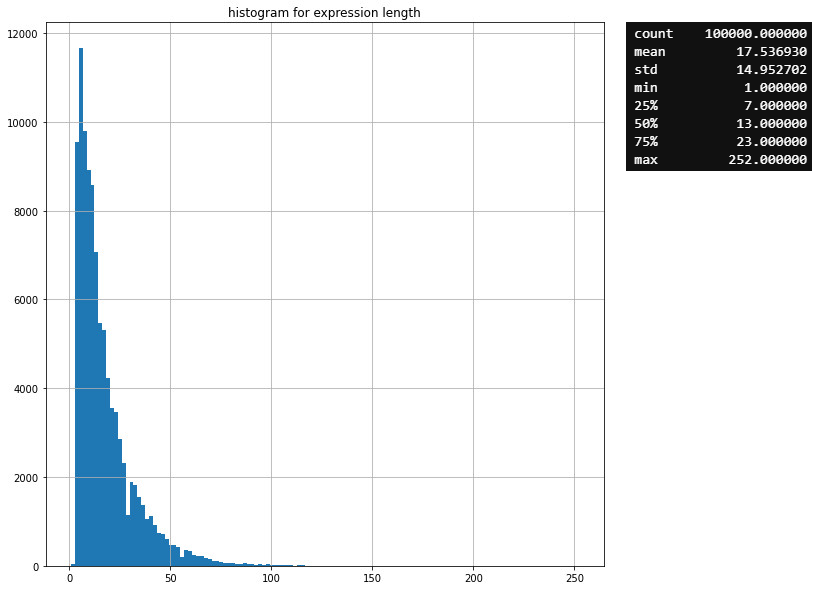
수식의 길이가 가장 짧은 경우는 한 글자이고 가장 긴 경우는 252 글자로 되어 있다.
hypothesis
이미지를 관찰하다 보니 다음과 같은 궁금증이 생겼다.
- 수식을 인식하는데 이미지의 RGB가 필요한가? 흑백 이미지로 사용해도 되지 않을까?
- 원본 이미지의 해상도가 중요한가? 해상도가 줄어든다고 수식이 달라지지 않을 것이다.