image preprocessing
이전에 EDA에서 살펴봤듯이 주어진 이미지의 크기는 다양하다.
높이가 작은 하위 10개의 이미지 크기는 [(20, 72), (21, 53), (21, 73), (24, 49), (24, 71), (25, 41), (25, 59), (25, 91), (25, 187), (26, 49)]이다.
높이가 큰 상위 10개의 이미지 크기는 [(7783, 1099), (8471, 980), (8587, 779), (8670, 670), (8737, 881), (8950, 1380), (9037, 931), (9070, 1010), (9600, 930), (10020, 1359)]이다.
이대로 학습에 사용한다면 계산량이 많아서 학습이 느릴 것이다.
따라서 해상도가 큰 이미지는 줄여야 한다.
하지만 크기가 달라서 고정된 크기로 바꿔야할지 어떻게 해야할지 고민이 된다.
또한 CNN에 fully connected layer가 있다면 입력 이미지의 크기를 모두 동일하게 해야할 것이다.
혹은 fully connected layer 전에 adaptivepooling layer를 추가하면 입력 이미지의 크기가 동일하지 않아도 된다.
정리하면 이미지의 해상도를 어떻게 줄여야 할까? 전략은 다음과 같다.
- 가로보다 세로가 더 긴 이미지는 90도 회전한다.
- 세로의 길이가 더 긴 경우는 수식 이미지가 아래와 같은 경우이다.
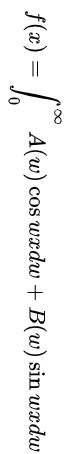 1
1
- 세로의 길이가 더 긴 경우는 수식 이미지가 아래와 같은 경우이다.
- aspect ratio(가로 / 세로)의 값이 15이상인 경우 가로의 길이를 세로 * 15가 되도록 줄인다.
- 픽셀의 갯수가 256x256 이상이라면 가로, 세로 비율을 유지하여 가로의 길이가 256이 되도록 줄이고 그렇지 않은 경우 그대로 사용한다.
위 전략에 문제점이 있다.
예를 들어 아래와 같이 올바른 이미지임에 불구하고 세로의 길이가 더 길다.
 2
2
이 경우 세로의 길이가 더 길어서 90도 회전을 한다면 오히려 잘못된 이미지가 된다.
이런 이미지를 수작업으로 찾기는 어려우므로 학습을 해보고 성능이 낮은 이미지를 추려서 전처리 과정에 예외로 추가할 예정이다.
그러므로 위 전략처럼 단순하게 진행할 것이다.
model architecture
이미지에서 feature map을 추출하는 모델은 가장 간단한 CNN을 사용할 예정이다.
추출한 feature map을 GPT 모델에 입력으로 하여 수식을 예측할 것이다.
GPT 모델은 huggingface 에서 제공하는 transformers library를 사용할 것이다.
pre-trained model을 제공해주지만 현재 프로젝트의 domain과 pre-trained model의 domain이 매우 다르므로 임의로 초기화된 모델에 pre-training을 할 예정이다.