object detection 1
Object detection is a computer technology related to computer vision and image processing that deals with detecting instances of semantic objects of a certain class (such as humans, buildings, or cars) in digital images and videos.
Well-researched domains of object detection include face detection and pedestrian detection.
Object detection has applications in many areas of computer vision, including image retrieval and video surveillance.
object detection은 디지털 이미지 혹은 비디오에서 특정 class(인간, 건물 혹은 차와 같은)의 semantic object들의 객체를 탐지하는데 사용하는 컴퓨터 비전과 이미지 처리에 관련된 컴퓨터 기술이다.
object detection 연구가 활발한 분야는 얼굴 탐지와 보행자 탐지이다.
object detection은 이미지 검색과 비디오 감시를 포함하여 컴퓨터 비전의 많은 영역에서 응용을 하고 있다.
참고로 이 글을 보면 face recognition과 face detection의 차이점을 설명한다.
똑같은 줄 알았는데 face detection은 좀 더 넓은 의미의 face recognition이다.
단순하게 이미지나 비디오에서 얼굴을 탐지하는 것이다.
face recognition은 누구의 얼굴인지 구분하는 biometric technology이다.

위 그림은 object detection의 예시이다.
원하는 것은 이미지 혹은 비디오에서 객체를 인식해서 탐지하고 분류하는 것이다.
탐지하기 위해서는 객체를 포함하는 가장 작은 box가 필요하다.
그리고 박스 안 객체가 어떤 class에 속하는지 분류해야 된다.
즉 필요한 것은 class와 box를 표현할 좌표이다.
이때 좌표는 (x, y) 두 쌍이 필요하다, 왼쪽 위와 오른쪽 아래.
신경망을 사용하기 전 전통적인 object detection 방법 두가지를 소개한다.
- HOG(Histogram Of Gradient)
나중에 추가… - selective search
나중에 추가…
신경망을 사용하여 이를 구현하는 architecture가 두가지, two-stage, single-stage detection, 가 있다.
먼저 two-stage detection 기법들을 살펴본다.
R-CNN(Regions with CNN features)
이 부분은 이 논문을 참조하여 작성하였다.
신경망을 이용한 object detection 모델의 지평을 열었다.
기존의 방법들보다 좋은 성능을 보였다.
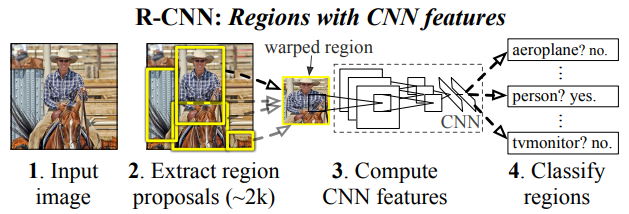
R-CNN의 과정을 설명하면 다음과 같다.
- 이미지를 입력한다.
- 이미지에 대해 region proposal을 여러 개 추출한다.
window sliding으로 이미지를 추출해서 모든 부분을 고려한다면 정확한 영역을 구할 수 있겠지만 계산량이 어마어마할 것이다.
그래서 R-CNN과 관련 없는 알고리즘, 이 논문에서는 selective search 사용함,으로 입력 이미지에 대해 약 2,000개의 region proposal을 추출한다.
selective search가 이미지를 보고 객체가 있을법한 부분을 crop해준다.
이 과정에서 시간이 많이 걸리고 많은 disk space가 필요하다. - 추출된 proposal을 정해진 크기로 resize하고 CNN으로 feature vector를 계산한다.
추출된 proposal은 서로 다른 크기를 갖는다.
CNN에 넣기 위해 비율을 고려하지 않고 일정한 크기로 resize를 한다(warping).
사전에 학습된 CNN(오래된 논문이라 AlexNet을 사용함)을 사용하는데 FC layer를 사용한다.
즉, 고정된 크기의 출력을 만들기 때문에 고정된 크기의 입력을 넣어야 한다.
그리고 proposal에 대한 feature vector를 계산한다. - class 예측과 bounding-box regression을 했다.
예측은 linear SVM을 사용했다.
regional proposal은 외부 알고리즘으로 생성되기 때문에 bounding-box를 올바르게 수정해야 된다.
실제 영역과 얼마나 겹치는지 알 수 있지만 정답처럼 예측할 수 없기 때문에 bounding-box regression을 도입했다.
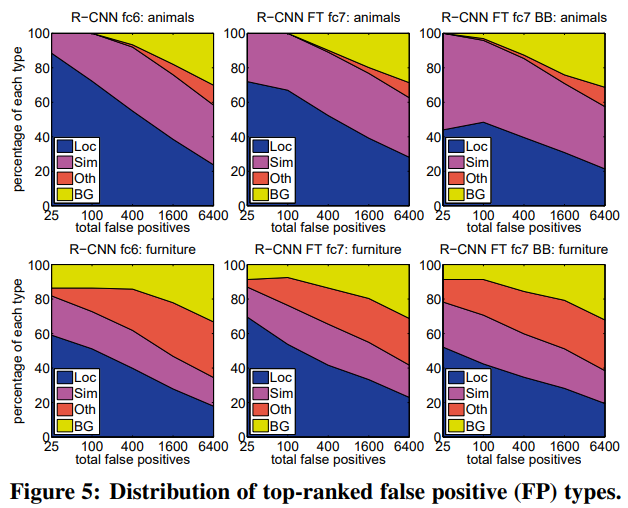
위 그림의 파란색Loc는 poor localization (a detection with an IoU overlap with the correct class between 0.1 and 0.5, or a duplicate)을 의미한다.
또 다른 이유는 pre-trained CNN을 사용하고 있는데 CNN은 positional invariance 특징을 가진다.
위치에 상관없이 객체의 특징을 얻을 수 있어서 분류 성능이 높기 때문에 정확한 위치를 얻는게 힘들다.
이런 취약점을 해결하기 위해 bounding-box regression을 도입했다.
training
위에서 간략하게 과정을 살펴봤는데 여기서는 학습에 대한 좀 더 구체적인 내용을 다룬다.
학습 데이터는 canonical PASCAL VOC를 사용했다.
R-CNN은 3가지 loss를 사용하며 각각에 대해 좀 더 알아본다.
log loss - fine-tuning network with softmax classifier
log loss는 CNN을 fine-tuning하기 위한 loss이다.
사전에 학습된 CNN은 ImageNet을 학습시켰다.
현재 사용하는 데이터에 대해 fine-tuning이 필요하다.
기존 classifier layer를 분류할 객체의 수가 N개라면 N+1(배경 포함하여)개의 class를 분류하도록 바꾸고 나머지는 바꾸지 않는다.
생성한 regional proposal 중 ground-truth와 IoU(Intersection of Union)를 계산하여 0.5가 넘으면 positive, 그렇지 않으면 negative proposal이라 한다.
 2
2
IoU는 Jaccard index랑 동일하며 object detection에서 유사함을 측정하는 measure로 사용한다.
학습할 때 32개의 positive와 96개의 negative(background proposal)을 사용한다.
배경에 비해 탐지할 객체가 매우 적기 때문에 동일한 갯수로 학습하지 않는다.
hinge loss - linear SVMs
fine-tuning에서 positive, negative sample 정의와 달리 여기서는 positive sample을 ground-truth boxes, negative를 IoU 0.3미만인 proposal로 사용한다.
그 외는 proposal은 무시한다.
class 마다 SVM을 학습시켜 객체인지 아닌지, 어떤 객체인지를 분류하도록 학습한다.
classifier로 SVM을 사용한 이유는 softmax를 사용했을 때보다 성능이 더 좋았다고 한다.
least square - bounding-box regression
localization performance를 향상시키기 위해 사용된다.
사용하는 데이터는 proposal $P$ 의 중심 좌표(x, y)와 너비와 높이를 의미하는 w, h를 사용하며 각각 $P_x, P_y, P_w, P_h$ 로 나타낸다.
비슷하게 ground-truth $G$ 의 데이터는 $G_x, G_y, G_w, G_h$ 이다.
그리고 다음과 같이 $G$ 를 예측한다.
\(\hat{G_x} = P_wd_x(P) + P_x\\
\hat{G_y} = P_hd_y(P) + P_y\\
\hat{G_w} = P_w\ exp(d_w(P))\\
\hat{G_h} = P_h\ exp(d_h(P))\)
$d_x(P), d_y(P), d_w(P), d_h(P)$ 는 proposal의 transformation과 관련된 값들이다.
\(w_\star = \underset{\hat{w_\star}}{\operatorname{argmin}}\sum_i^N(t_\star^i - \hat{w_\star}^T\phi_5(P^i))^2 + \lambda \parallel \hat{w_\star} \parallel^2\)
$\phi_5$ 는 P에 대한 CNN에서 pool5 feature map이고 $\hat{w_\star}$ 는 학습가능한 weight이고 $\star$ 에는 {x, y, w, h}가 해당된다.
$t_\star$ 은 아래와 같다.
\(t_x = (G_x - P_x) / P_w\\
t_y = (G_y - P_y) / P_h\\
t_w = log(G_w / P_w)\\
t_h = log(G_h / P_h)\)
bounding-box regression하면서 두가지 사소한 문제가 있었다.
하나는 regularization parameter $\lambda$ 의 값을 정하는 문제다.
여기서는 1000을 선택했다.
두번째는 proposal P가 너무 ground-truth G와 다르면 학습이 잘 안되는 문제가 있다.
그래서 IoU가 0.6인 proposal을 사용했고 나머지는 버렸다.
test
test 이미지에 대해 regional proposal을 만들고 각각 class 분류와 bounding-box를 구하고 NMS(Non-Maximum Suppression)을 수행한다.
 3
3
NMS는 위와 같이 여러 후보 proposal을 줄여주는 알고리즘이다.
아래 코드는 NMS를 구현한 것이고 여기서 가져왔다.
def nms(boxes, probs, threshold):
"""Non-Maximum supression.
Args:
boxes: array of [cx, cy, w, h] (center format)
probs: array of probabilities
threshold: two boxes are considered overlapping if their IOU is largher than
this threshold
Returns:
keep: array of True or False.
"""
order = probs.argsort()[::-1]
keep = [True]*len(order)
for i in range(len(order)-1):
ovps = batch_iou(boxes[order[i+1:]], boxes[order[i]])
for j, ov in enumerate(ovps):
if ov > threshold:
keep[order[j+i+1]] = False
return keep
또한 이 슬라이드는 yolo에 대해 설명하고 있지만 NMS에 대한 설명이 자세하게 있어서 많은 도움이 되었다.
limitation
과정은 간단해 보이지만 어려운 점이 있다.
이미지 내 proposal을 찾는 과정이다.
proposal은 신경망과 상관없는 알고리즘에 의해 얻으므로 end-to-end 모델이 아니다.
학습이 되지 않으며 사람의 지식이 들어가서 얻은 proposal이므로 성능 향상에 한계가 존재했다.
또한 한 이미지(original image)에 대해 여러 개의 이미지(proposal)를 추출하고 이 갯수만큼 CNN을 계산한다.
이 부분에서 많은 bottleneck이 생긴다.
그래서 GPU로 실행하면 대략 이미지 한 장에 13초가 걸렸다.
CNN, SVM, bounding-box regression 각각 모델이 필요하며 SVM과 bounding-box regression은 CNN을 학습시키지 못한다.
SPPNet(Spatial Pyramid Pooling Network)
이 부분은 이 논문과 이 글을 참조하여 작성하였다.
R-CNN에서의 한계점 중 하나인 수 많은 regional proposal에 대해 CNN에 통과시켜 feature vector를 얻었다.
이 과정은 computational cost가 많이 발생한다.
여기서는 한 이미지를 CNN 한번만 계산하여 개선했다.
또 다른 한계점은 고정된 크기의 이미지를 입력해야 된다.
앞서 설명했듯이 그 이유는 classifier layer가 FC layer이므로 고정된 크기의 입력이 필요하기 때문이다.
이미지 안에 임의의 크기를 가지고 있는 객체를 고정된 크기로 만든다면 성능이 감소할지 모른다.
여기서 제안하는 SPP(Spatial Pyramid Pooling)로 이미지 크기와 상관없이 고정된 크기의 representation을 얻을 수 있으며 형태가 자유로운 객체에 강건하다.
참고로 SPP는 기존 computer vision에 있는 방법이며 딥러닝에 적용한 것이다.
논문에서 이해가 안되는 부분은 Bag-of-Word이 언급되는데 SPP와 어떻게 연관있는지 이해가 안된다…
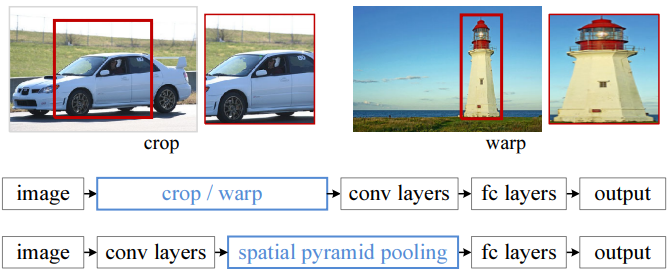
위 그림은 R-CNN과 차이를 나타낸다.
R-CNN은 한 이미지로부터 수차례 CNN을 계산하지만 SPPNet은 오직 한번만 계산한다.
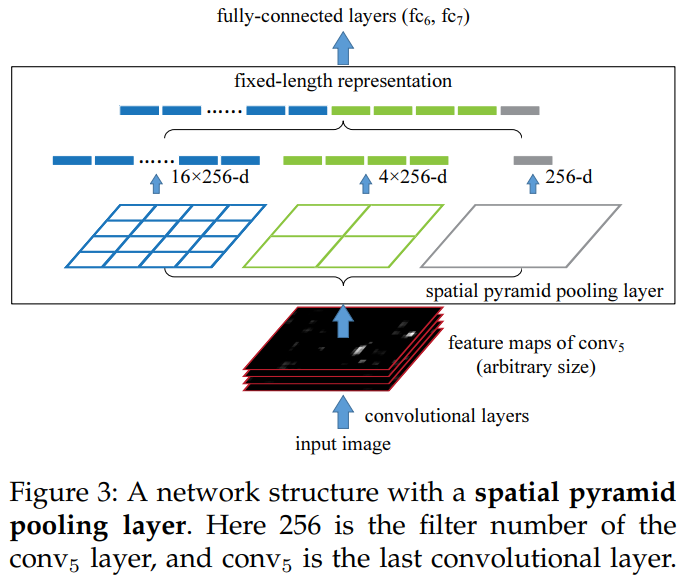
위 그림을 통해 SPP 과정을 살펴보자.
먼저 학습 이미지의 크기를 동일하게 resize했다.
이론적으로 임의의 크기를 학습할 수 있지만 GPU 프로그래밍에서는 동일한 크기의 이미지를 선호했다.
한 epoch은 180x180 크기로 학습하고 다음 epoch은 224x224 크기로 번갈아 학습했다.
입력의 크기가 다르지만 학습되는 network는 동일하므로 가변 입력을 흉내냈다.

사전에 n-level pyramid(여기서는 3-level로서 3x3, 2x2, 1x1)을 정의한다.
a x a feature map을 적절한 window size와 stride로 pooling하여 3x3, 2x2 1x1 feature map으로 만든다.
window size는 ceiling(a / n), stride는 flooring(a / n)으로 정하면 된다.
이렇게 해서 얻은 feature map을 1-D vector로 만든 다음 concatenation한다.
이 같은 방법으로 입력이 180x180, 224x224 이더라도 동일한 크기의 feature vector를 얻을 수 있다.
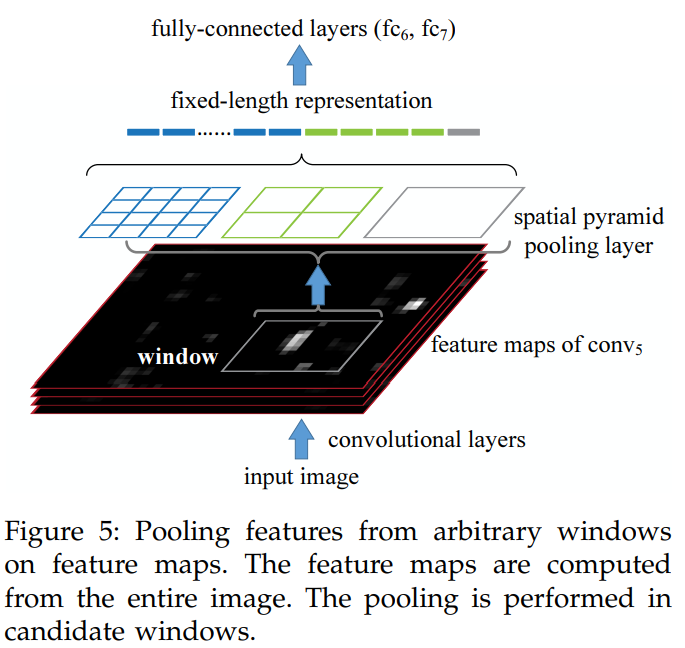
object detection에서 SPP 과정을 살펴본다.
여기서도 학습 이미지의 크기를 통일시켰다.
feature map을 얻고 이에 대해 regional proposal들을 얻는다.
이것들에 대해 n-level pyramid(여기서는 4-level로서 6x6, 3x3, 2x2, 1x1)를 적용하여 feature map을 얻는다.
그리고 1-D vector로 만든 다음 concatenation한다.
이후 과정은 R-CNN과 동일하다;SVM을 사용해 classification하고 bounding-box regression 한다.
SPPNet의 특징을 다음과 같이 정리해봤다.
- 다양한 크기의 입력에 대해 동일한 크기의 feature vector를 얻을 수 있다.
- feature map을 여러가지 크기로 pooling하여 국소적인 정보를 유지했다.
- R-CNN과 달리 CNN을 한번만 계산하므로 많은 비용을 줄여서 학습속도가 빠르다.
- 여전히 end-to-end로 학습하지 못한다.
fast R-CNN
이 부분은 이 논문과 이 글과 이 글을 참조하여 작성하였다.
fast R-CNN은 SPPNet과 유사하다.
차이점은 SPPNet은 pooling으로 SPP를 사용했고 fast R-CNN은 ROI pooling을 사용했다.
여기서 ROI는 Region Of Interest로 관심영역을 의미한다.
이전에 논문들에서 언급된 regional proposal과 동일한 의미이다.
여기서는 ROI라고 하겠다.
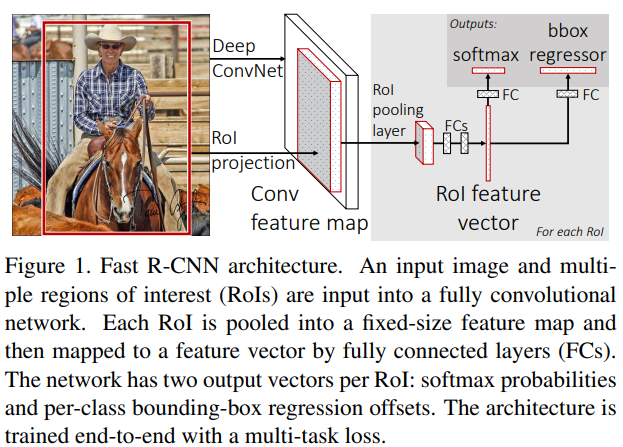
fast R-CNN의 과정은 다음과 같다.
- origin image에서 ROI를 추출한다.
selective search와 같은 딥러닝과 상관없는 알고리즘으로 수 많은 ROI를 추출한다. - origin image를 CNN에 통과시켜 feature map을 얻는다.
- ROI에 대응하는 feature map의 일부분을 얻는다(ROI projection).
projection을 하기 위해서는 얼마나 subsampling을 했는지 아는게 중요하다.
예를 들어 origin image의 크기가 18x18이고 feature map의 크기가 3x3 이면 크기가 1/6배 줄었다.
그럼 ROI의 중심좌표 (x, y)와 너비, 높이에 1/6을 곱하면 된다.
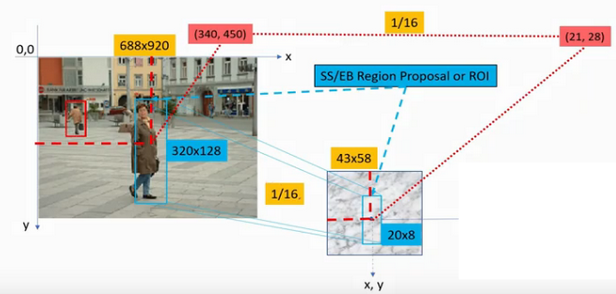
위 그림을 예시로 보면 중심좌표가 340x450, 높이x너비가 320x128인 ROI가 있다.
이 때 subsampling의 비율은 1/16배이다.
즉, origin image에 비해 1/16배 줄어든 feature map이다.
ROI에 대응하는 feature map의 중심좌표는 (340 / 16, 450 / 16) $\simeq$ (21, 28), 높이x너비는 (320 / 16, 128 / 16) = (20, 8)이 된다. - ROI pooling을 통해 고정된 크기의 feature map을 얻는다(ROI pooling).
ROI pooling은 사실 앞서 살펴본 SPP의 1-level pyramid라고 볼 수 있다.
ROI projection을 하여 얻은 feature map은 크기가 다양하다.
이를 사전에 정의한 feature map으로 pooling을 한다.
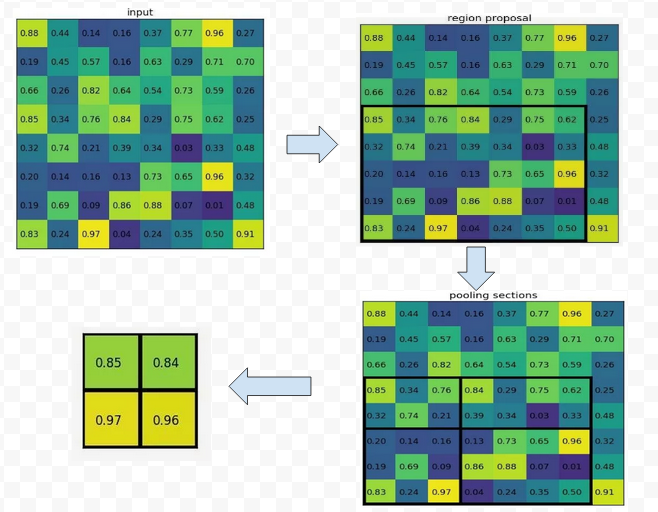
위 그림을 예시로 보면 proposal에 대응하는 feature map(오른쪽 위 검은색 박스 영역)을 사전에 정의한 크기 2x2로 pooling한다.
동일한 비율로 영역을 나눠서 영역 중 가장 큰 값을 가져온다.
여기서는 7x5인데 정확하게 나누어 떨어지지 않아도 된다. - 각 feature map에 대해 FC layer에 통과하여 고정된 크기의 ROI feature vector를 얻는다.
ROI pooling을 통해 얻은 feature map을 1-D vector로 바꾸고 FC layer를 통과하여 ROI feature vector를 얻는다. - classification과 bounding-box regression을 한다.
multi-task loss
SPPNet과 차별화된 부분은 학습에 있다.
R-CNN에서부터 문제점가 되었던 부분으로 classification과 bounding-box regression으로 CNN을 학습하지 못했다.
pre-trained network를 사용하며 CNN을 학습하는 것은 사실 fine-tuning이다.
이전에는 classifier로 SVM을 사용했지만 여기서는 softmax를 사용한다.
또한 bounding-box regression으로 L2 loss를 사용했지만 여기서는 smooth L1을 사용한다.
그래서 multi-task loss를 다음과 같이 정의한다.
\(L(p, u, t^u, v) = L_{cls}(p, u) + \lambda[u \ge 1]L_{loc}(t^u, v)\)
$L_{cls}$ 는 classification loss(cross-entropy)를 의미하며 $p$ 는 class에 대한 discrete probability distribution(softmax output)을 의미하며 배경을 포함한 $K+1$ 차원의 벡터이다.
$u$ 는 ground-truth class label이다.
$L_{loc}$ 는 bounding-box regression을 의미한다.
$t^u, v$ 는 예측, ground-truth coordinate이다.
$L_{loc}(t^u, v)$ 를 좀 더 살펴보면 다음과 같다.
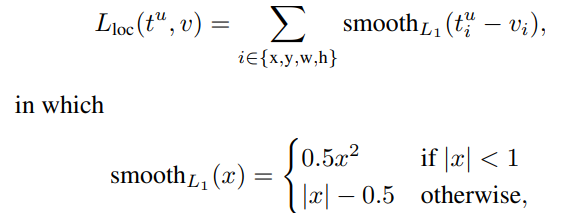
논문에서는 SPPNet과 R-CNN처럼 $L_2$ 를 쓰는 것보다 $L_1$ 를 쓰는 것이 outlier에 대해 덜 sensitive하다고 한다.
여기서 $v$ 의 값을 제한하지 않을 때(when the regression targets are unbounded) $L_2$ loss로 학습할 때 learning rate를 잘 선택해야 된다, gradient exploding이 일어날 수 있다.
그래서 $v$ 의 값을 평균이 0, 분산이 1로 normalization 했다.
$[u \ge 1]$ 은 $u$ 가 1이상이면 1, 그렇지 않으면 0을 반환하는 함수이다.
여기서 배경의 label은 0이다.
즉, 배경에 대해서는 bounding-box regression을 하지 않는다.
$\lambda$ 는 classification loss와 bounding-box regression loss의 균형을 조절하여 여기서는 1을 선택했다.
mini-batch sampling
mini-batch는 R개의 ROI를 학습하는데 N개의 이미지에서 각각 $R/N$ 개의 ROI를 균등하게 샘플링한다.
이것은 R개의 이미지에서 1개의 ROI를 샘플링하여 학습하는 것보다 효율적이다(N이 작을수록 시간복잡도가 낮아진다).
이 방식을 여기서는 hierarchical sampling이라 한다.
ROI는 IoU 0.5 이상인 것에 class를 부여하고 0.1 ~ 0.5인 ROI는 배경으로 학습한다.
ROI의 1/4는 positive를 사용한다.
scale invariant
이미지의 다양한 크기의 객체를 학습하기 위해 두가지 방법을 사용했다.
- brute force(single scale)
모든 이미지의 크기를 동일하게 만들었다.
이는 실제 객체의 크기에 왜곡이 있을 수 있는데 이것을 무시하고 학습하길 바라는 것이다. - image pyramid(multi scale)
이미지를 여러 크기로 만들었다.
실험 결과 single scale의 결과가 multi scale의 결과와 거의 비슷했다.
그래서 multi scale을 사용하지 않고 single scale을 사용했다.
정리하자면 다음과 같다.
- R-CNN, SPPNet과 달리 classification, bounding-box regression으로 CNN을 학습할 수 있다.
- 여전히 ROI는 외부 알고리즘에 의해 생산된다.
- classifier로 SVM을 사용해봤는데 softmax의 성능이 약간 더 좋았다.
- FC layer를 통과할 때 SVD를 사용하여 inference time을 감소시켰다.
faster R-CNN
이 부분은 이 논문과 이 글을 참조하여 작성했다.
fast R-CNN은 이전 모델들, SPPNet, R-CNN,보다 빠른 실행시간을 갖는다.
하지만 이미지로부터 ROI를 추출하는데 여전히 딥러닝과 관계없는 알고리즘을 사용한다.
이 연구에서는 RPN(Region Proposal Network)를 제안한다.
이 network는 detection, classification network를 공유한다.
즉, 하나의 network에서 proposal을 생산과 detection, classification을 할 수 있다.
RPN은 end-to-end로 학습할 수 있다.
그래서 여기서 소개할 faster R-CNN은 RPN과 fast R-CNN을 합친 single network이다.
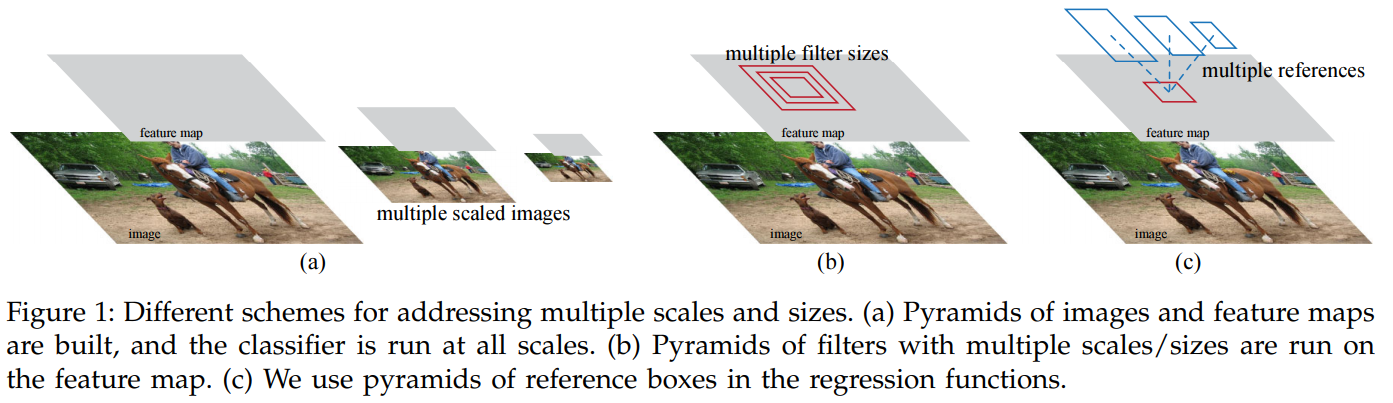
위 그림을 보면 다양한 크기를 가진 이미지를 처리하기 위해서는 이미지를 여러 크기로 만들어 feature map을 추출할 수 있다.
혹은 다양한 크기의 filter를 사용할 수 있다.
여기서는 단일 크기의 이미지에 대해 다양한 크기의 bounding-box를 사용한다.
즉, 한 영역에 대해서 다양한 크기의 bounding-box 후보를 생각하는 것이다.
그래서 bounding-box가 얼마나 변경하는지 학습하여 실제와 유사하게 만드는 것이다.
이 논문에서 bounding-box 후보를 anchor라고 부르고 사전에 모양과 크기를 정한다.
여기서 두가지 module 혹은 stage를 정의한다.
region을 생산하는 network, RPN과 region을 이용하는 fast R-CNN detector이다.
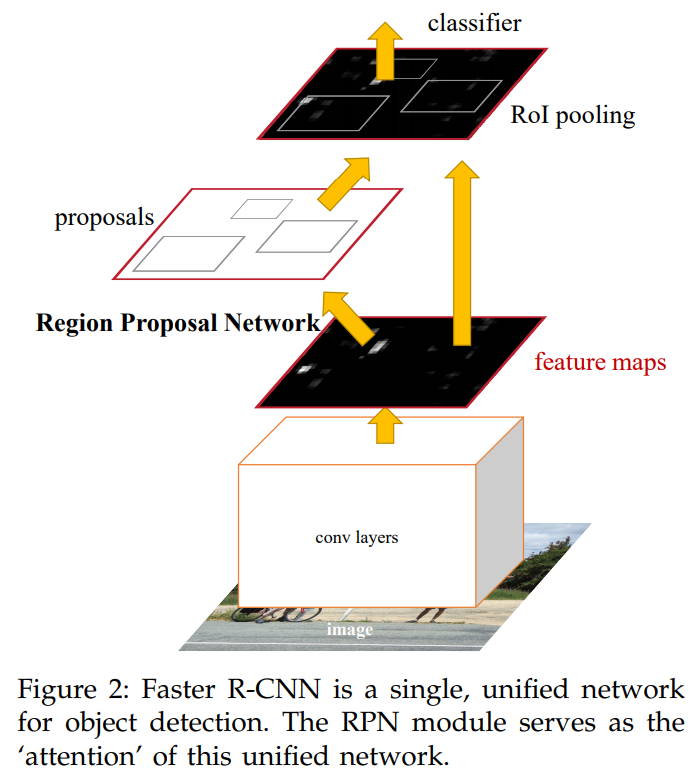
위 그림은 faster R-CNN의 구조를 나타낸다.
conv layers는 RPN, detector가 공유한다.
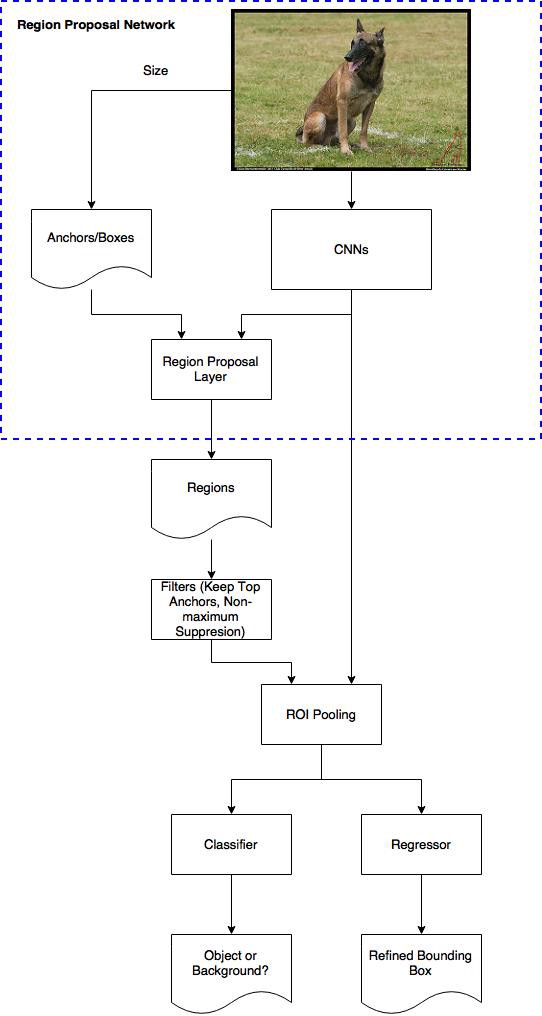
여기서 RPN, 점선으로 된 박스,에 대해 좀 더 알아본다.
RPN(Region Proposal Network)
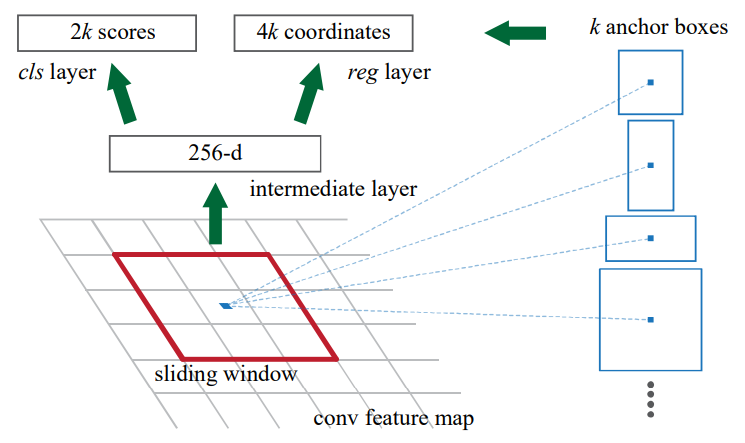
임의의 크기의 이미지를 CNN에 통과하여 feature map을 얻는다.
이 feature map에 대해 n x n convolution을 한다(이 논문에서는 3x3을 사용했다).
이 때 channel의 수는 앞선 CNN이 ZFNet이면 256, VGG16이면 512로 한다.
그리고 1x1 conv로 channel을 줄이는데 classification layer는 2k, bounding-box regression layer는 4k로 한다.
여기서 k는 anchor의 갯수이다.
예를 들어 CNN에서 14x14xC feature map을 얻었다고 하자.
그러면 3x3x256 conv를 통과하여 14x14x256 feature map을 얻고 1x1x4k conv를 통과하여 14x14x4k를 얻는다.
이 feature map의 한 픽셀의 의미는 k개의 bounding-box coordinate(x, y, w, h)를 의미한다.
즉, 한 픽셀에 대한 k 종류의 bounding-box 후보를 예측한 것을 의미한다.
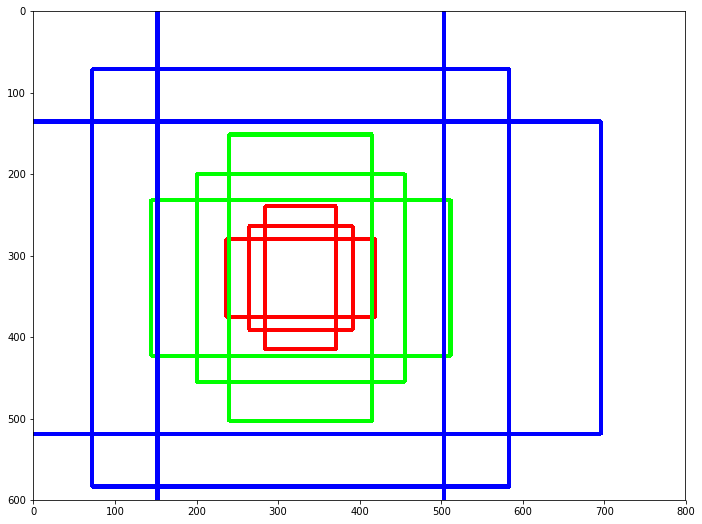
위 그림에서 (320, 320)의 픽셀에 대해 9개의 bounding-box를 확인할 수 있다.
이것들을 anchor라고 한다.
이 논문에서는 3가지 크기와 3가지 높이, 너비 비율을 사용하여 bounding-box 후보를 사전에 정의하고 있다.
이렇게 여러가지 크기와 모양을 가진 anchor들은 다양한 크기의 객체를 잘 포착(capture)할 수 있다.
또한 anchor는 translation invariant 특성을 가지는데 객체가 이동하더라도 상관없이 객체를 잘 포착할 수 있다.
예를 들어 A라는 object를 anchor i가 (x1, y1)에서 발견했다고 하자.
(x2, y2)로 object A를 이동시킨다면 anchor j가 이를 발견할 수 있다 는 의미이다.
origin image에 대해서 모든 픽셀마다 bounding-box 후보를 고려하는게 아니라 CNN에서 얻은 feature map의 픽셀에 대해 고려한다.
feature map의 사이즈를 보면 origin image에서 얼마나 subsampling 했는지 알 수 있다.
즉, feature map에서 (i, j)는 origin image에서 (r * i, r * j) 일 것이다, r은 subsampling 비율이다.
(r * i, r * j)에서 9개의 anchor를 고려하는데 origin image를 벗어나는 anchor는 고려하지 않는다.
또한 이 anchor들을 positive, negative sample로 구분을 해야되는데 positive는 다음 두가지 기준 중 하나라도 만족하면 된다.
- ground-truth와 IoU가 가장 높은 anchor들
- ground-truth와 IoU가 0.7 이상인 anchor들
보통 두번째 조건에서 positive sample이 결정되지만 이에 해당되지 않는 경우가 간혹 있어서 첫번째 조건을 추가했다.
하나의 ground-truth가 여러 anchor들을 positive sample로 만들 수 있다.
negative sample은 IoU가 0.3이하인 경우에 해당한다.
그 외 anchor들은 무시한다.
다시, 아까 bounding-box regression을 위해 14x14x4k feature map을 얻었다.
한 픽셀을 보면 4k 벡터이다.
k개의 ground-truth와 bounding-box regression을 한다.
비슷하게도 classification layer의 feature map은 14x14x2k이다.
2k의 의미는 k개의 bounding-box가 객체를 포함하는지 아닌지를 나타낸다(k * 2).
객체인지 아닌지는 이진분류이므로 굳이 class 2개를 사용하지 않고 1개를 사용해도 된다.
여기서 객체의 class를 분류하지 않고 객체인지 아닌지 분류하는 이유가 뭘까?
RPN은 selective search와 같은 regional proposal을 추출하는 역할이다.
객체가 있을 것 같은 곳을 추출하는게 목적이다.
그래서 class를 분류하지 않고 객체가 있는지 없는지 유무만 확인하는 것이다.
class 분류는 fast R-CNN detector가 하기 때문이다.
이 논문에서는 이 값을 objectness score라 부른다.
RPN의 loss는 아래와 같이 fast R-CNN과 거의 유사하다.
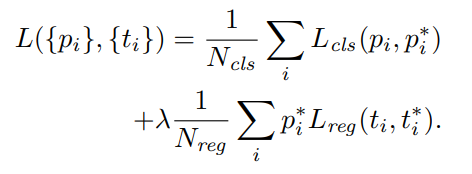
$i$ 는 $i$ 번째 anchor를 의미하고 $p_i$ 는 $i$ 번째 anchor가 객체일 확률이고 $p_i^\star$ 는 $i$ 번째 anchor가 positive 일 때 1, 그렇지 않으면 0이다.
다시 말해, negative sample일 때 bounding-box regression을 하지 않는다.
$N_{cls},\ N_{reg}$ 는 정규화 계수이고 나머지는 fast R-CNN에서 loss와 동일하다.
이 논문에서는 $\lambda$ 를 10으로 정했다.
fast R-CNN에서 사용하기 위해 수 많은 ROI 중 NMS를 이용하여 중복되는 bounding-box를 제거한다.
학습에는 positive, negative sample을 50:50 비율로 사용했다.
training
이 부분은 이 슬라이드를 참조했다.
RPN과 fast R-CNN의 학습과정을 살펴본다.
두 network는 feature map을 생산하는 CNN을 공유한다.
공유된 feature를 학습하는 방법이 필요하다.
- 먼저 CNN을 ImageNet으로 사전 학습하고 이 모델을 M0이라 하자.
- M0을 기반으로 RPN을 학습하고 CNN은 fine-tuning하며 이 모델을 M1이라 하자.
- M1에서 ROI를 생산하는데 이를 P1이라 하자.
- M0과 P1를 사용하여 detector를 학습하고 이 모델을 M2라 하자.
CNN은 fine-tuning한다. - M2의 CNN은 detector에 의해 학습이 된 상태이다.
이 부분을 고정하고 다시 RPN을 학습하고 이 모델을 M3라 하자. - M3로 ROI를 생산하고 이를 P2라 하자.
- M3의 CNN을 고정하고 P2와 함께 detector를 학습하고 이 모델을 M4라 하자.
experiment
나중에 추가…
YOLO(You Only Look Once)
나중에 추가…
SSD(Single Shot Detection)
나중에 추가…
CNN visualization
나중에 추가…