semantic segmentation
computer vision에서 image segmenation이란 다음과 같다.
image segmentation is the process of partitioning a digital image into multiple segments (sets of pixels, also known as image objects).
The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze.
Image segmentation is typically used to locate objects and boundaries (lines, curves, etc.) in images.
More precisely, image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics.
The result of image segmentation is a set of segments that collectively cover the entire image, or a set of contours extracted from the image.1
image segmentation은 디지털 이미지를 여러 segment(픽셀의 집합)들로 분할하는 과정이다.
segmentation의 목적은 이미지의 표현을 좀 더 의미있고 분석하기 쉬운 무언가로 바꾸는 것이다.
image segmentation은 전형적으로 이미지에서 object나 경계(선, 곡선 등)를 찾는데 사용된다.
더 정확하게 말하면, 이 과정은 같은 label을 가진 픽셀들이 어떤 특성을 공유하는 모든 픽셀을 label로 할당하는 것이다.
그 결과 이미지 전체를 포괄하는 segment의 집합 혹은 이미지에서 추출된 contour 집합이 된다.
다음은 위키피디아의 image segmentation 내 semantic segmentation에 관한 내용이다.
Semantic segmentation is an approach detecting, for every pixel, belonging class of the object. For example, when all people in a figure are segmented as one object and background as one object.
semantic segmentation은 모든 픽셀에 대하여 object의 class를 탐지하는 방법이다.
예를 들어 figure 안에 모든 사람들과 배경은 각각 하나의 object로 세분화 된다.
image segmentation과 semantic segmentation을 살펴봤을 때 차이를 명확하게 말 못하겠다.
굳이 차이를 말해본다면 semantic segmentation은 픽셀 레벨에서 이미지 안에 무엇이 있는지 인식하고 이해하는 과정인 것 같다.
반면 image segmentation은 의미를 따지지 않고 픽셀들을 세분화하는 것 같다.
이 두개를 구분하는 것이 의미있는지 모르겠다…
image classification는 이미지 전체를 어떤 class로 분류하는 것으로서 segmentation과 차이는 명확하다.
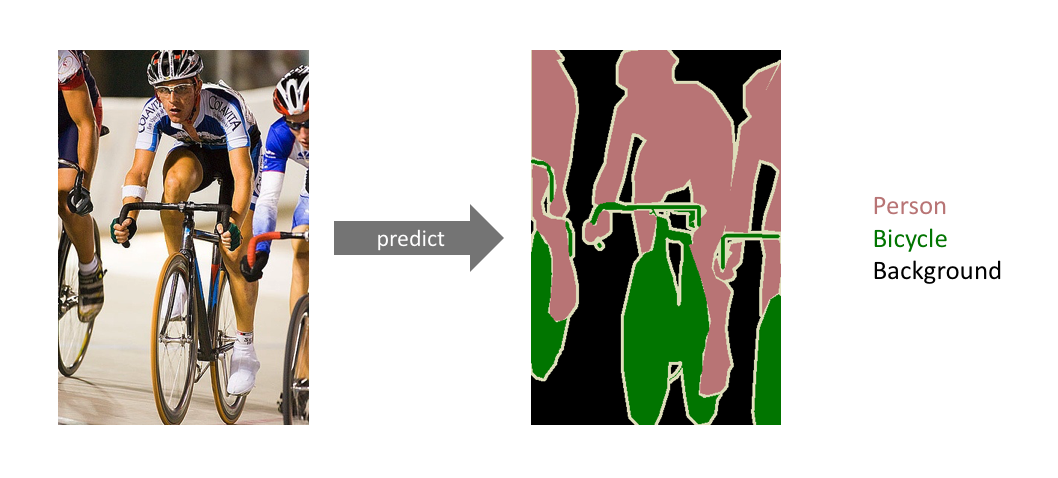 2
2
위 그림을 보면 semantic segmentation의 특징은 person으로 분류한 object들을 구분하지 않고 하나의 person class로 분류한다.
다음은 semantic segmentation architecture에 대해 알아본다.
FCN(Fully convolutional Network) 3
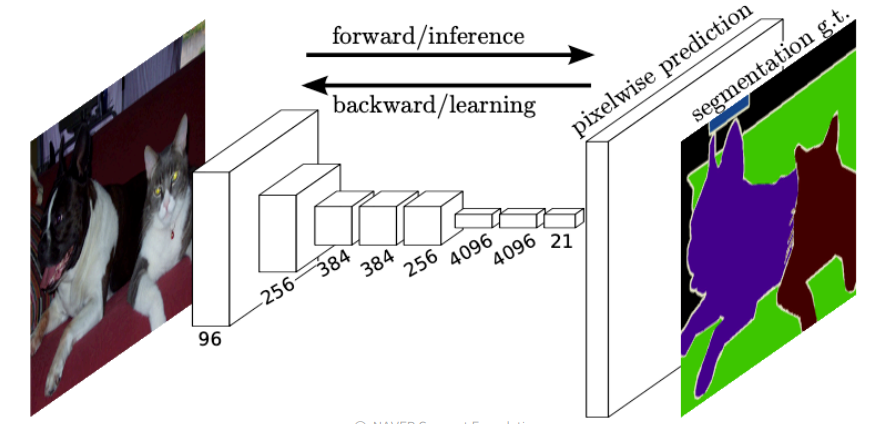
FCN의 특징을 살펴본다.
- semantic segmentation에 대한 최초 end-to-end 모델이다.
이전에는 사람들이 직접 어떤 구조를 만들고 특징을 추출하여 segmentation을 했다.
데이터가 많더라도 학습가능한 부분이 제한적이었다.
이를 근거로 만든 모델보다 end-to-end로 만든 신경망 모델의 성능이 훨씬 좋아졌다. - 임의의 입력 사이즈에 대해 동일한 사이즈의 segmentation map을 만들 수 있다.
이미지의 사이즈는 다양하다.
이미지 분류모델을 만들때 항상 이미지 크기를 고정했었다.
그 이유는 분류를 위한 FC(Fully Connected) layer가 고정된 크기의 입력을 받아 고정된 크기의 출력을 반환하기 때문이다.
하지만 FCN은 모든 이미지를 하나의 사이즈로 바꾸지 않아도 원하는 결과를 얻을 수 있다.
가능한 이유는 마지막 layer를 FC layer가 아닌 1x1 convolution layer를 사용했기 때문이다.
1x1 convolution layer와 FC layer를 좀 더 자세히 비교해보자.
FC layer는 weight matrix와 bias matrix로 되어 있으며 입력 행렬 X에 대하여 $XW+b$ 를 계산한다.
이때 $X$ 의 column 수와 W의 row 수가 일치해야 된다.
만약 입력 이미지의 사이즈, width, height, 가 다르다면 $X$ 의 column 수는 달라질 것이고 $XW+b$ 를 계산하지 못할 것이다.
하지만 1x1 convolution filter는 $X$ 의 사이즈와 상관없이 convolution을 할 수 있다.
그럼 semantic segmentation을 할 때 이미지의 사이즈를 고정하고 FC layer를 쓰면 안될까?
FC layer 사용하는 것은 적절하지 않다.
semantic segmentation은 spatial information이 중요하며 FC layer는 이 정보를 잃게 되고 convolution은 유지할 수 있다.
convolutional layer는 입력 사이즈가 크면 출력 사이즈도 커진다.
예를 들어 16x16 사이즈의 이미지를 입력해서 4x4 사이즈의 feature map을 얻는다면 100x100 사이즈의 이미지를 입력하면 25x25 사이즈의 feature map을 얻는다.
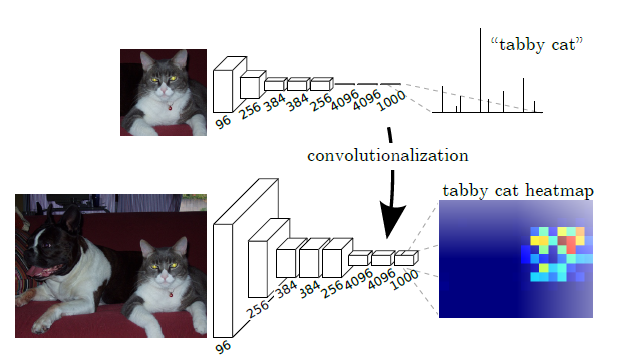
FC layer를 convolutional layer로 바꾸는 것을 convolutionalization이라 한다.
이로 인해 분류 network에서 이미지에 대한 heatmap을 출력하는게 가능해졌다.
convolutional layer와 pooling layer를 반복 사용하여 얻을 수 있는 것은 receptive field가 점점 커지며 이미지의 부분적으로 흩어져 있던 특징들을 하나로 모으고 단순한 특징에서 복잡한 특징이다.
또한 이미지 사이즈를 줄여 parameter 수를 줄일 수 있다.
그 결과 원래 사이즈에서 작은 사이즈의 feature map을 얻는다.
특징은 작은 사이즈에 이미지에서 얻은 feature를 담아내어 coarse하다.
전역적인 특징을 가지고 있다.
반대로 사이즈가 큰 feature map은 국소적이고 fine한 특징이 있다.
우리는 원래 사이즈와 동일한 출력을 얻어서 픽셀마다 class를 할당하고 싶다.
그래서 다시 사이즈를 키우는 작업이 필요하다.
이 과정을 Upsampling이라 하고 pooling layer과 같은 작업을 downsampling이라 한다.
upsampling
여기에 정리했다.
다시 논문으로 돌아와서 FCN의 출력값을 얻는 과정을 설명한다.
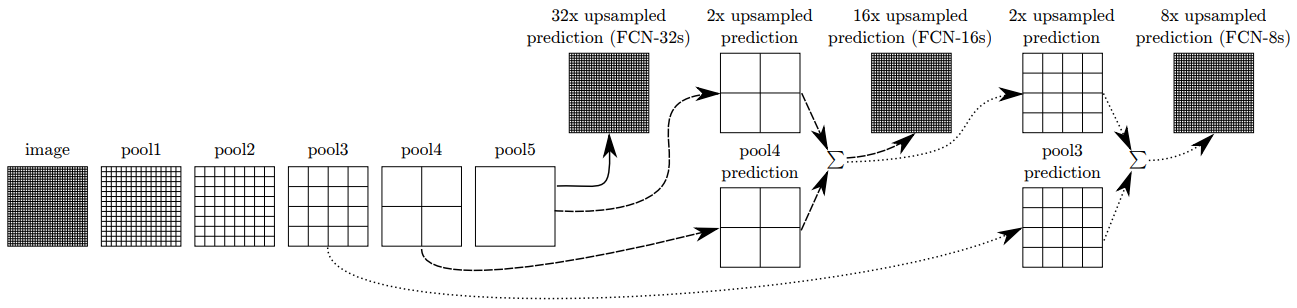
마지막 feature map을 사용하기에는 spatial information이 많이 손실되었다.
그래서 skip connection을 제안했다.
여러 사이즈의 feature map을 사용하여 손실되었던 spatial information을 얻을 수 있다.
위 그림은 upsampling하여 입력 이미지의 사이즈와 맞추는 과정을 보여주며 마지막 feature map인 pool5 이외에 pool4, pool3을 사용하고 있다.
pool1, pool2, … 사이에는 convolutional layer가 있으며 생략했다.
pool5는 원래 사이즈에 비해 1/32배 줄었기 때문에 크기를 32배 늘렸다.
이를 FCN-32s라 부른다.
FCN-16s는 pool5를 2배 upsampling하고 1x1 conv 연산으로 출력 channel을 class 수로 바꾼다.
그리고 pool4도 1x1 conv 연산으로 출력 channel 수를 바꾸고 pool5와 더하고 16배 늘린다.
FCN-8s도 위와 비슷하다.
우리가 최종적으로 원하는 출력은 입력 사이즈와 같고 channel의 수는 class 수이다.
그래야 픽셀마다 값이 가장 높은 class를 선택할 수 있기 때문이다.
결과는 다음과 같다.

위 그림에서 FCN-8s는 FCN-32s, FCN-16s, FCN-8s를 다 더한 것을 사용했다는 의미이다.
SDS는 이전의 최신 모델인 것 같다.
learning deconvolution network for semantic segmentation
나중에 추가…
hypercolumn
나중에 추가…
full-resolution residual networks for semantic segmentation in street scenes
나중에 추가…
U-Net 4 5
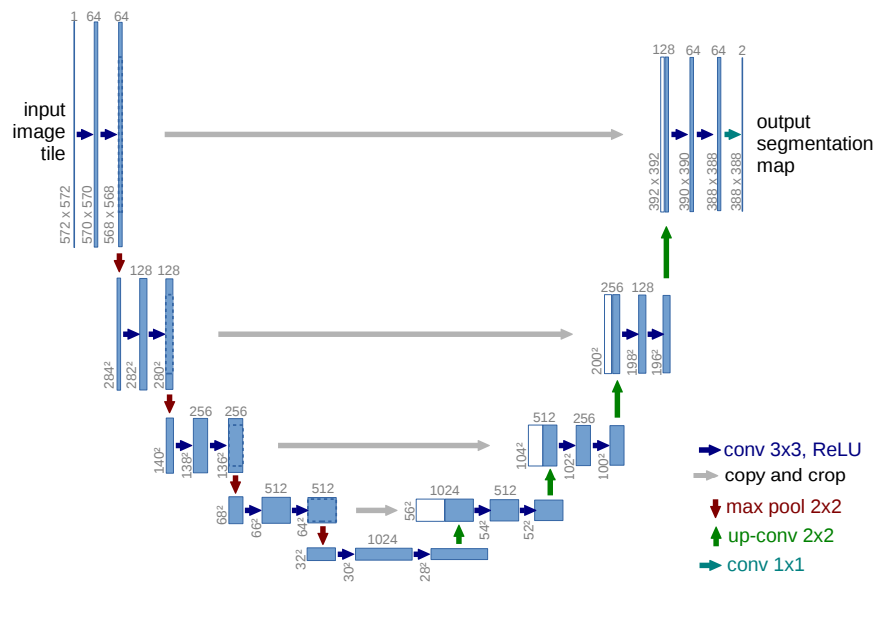
U-Net은 Biomedical 분야에서 image segmentation을 위해 개발된 CNN이다.
이 모델은 앞서 살펴본 FCN을 기반으로 한 모델이며 적은 수의 이미지로도 학습이 가능하도록 만들어졌다.
학습 이미지를 window sliding으로 작은 patch로 나누어서 network의 입력으로 사용한다.
만약 학습 이미지의 사이즈가 8x8이고 window 사이즈가 2라면 4x4=16개의 patch로 나눈다.
즉, stride가 window 사이즈가 되도록 patch를 얻는다.
stride=1으로 patch를 나누지 않는 이유는 중복되는 부분이 있기 때문이다.
논문에서 가정하기를 이미 한번 network에 사용된 부분은 다시 사용안해도 된다 이다.
또한 patch가 많아져서 계산량이 많아 진다.
위 그림은 U-Net의 구조를 잘 설명하고 있다.
대략적으로 설명한다면 2번의 3x3 convolution과 1번의 maxpooling이 반복되며 이 과정을 contracting path라 한다.
이미지의 사이즈가 어느정도로 작아지면(여기서는 28x28까지 줄임) up-convolution을 하고 2번의 convolution을 하며 이 과정을 expanding path라 한다.
좀 더 자세히 설명하면 convolution을 할 때 feature map의 가장자리의 정보를 버린다.
즉, convolution할 때 padding을 사용하지 않아서 약간씩 feature map의 크기가 줄어든다.
maxpooling은 feature map의 사이즈를 1/2배 줄이고 channel 수를 2배 증가시킨다.
몇번의 maxpooling 이후에 expanding path로 넘어간다.
먼저 2x2 up-convolution을 한다.
up-convolution은 feature map의 사이즈를 늘려주고 채널을 1/2배 줄인다.
이때 이 layer의 대칭인 contracting path의 feature map을 가져와 concatenation을 한다.
이 path에서 가져올 때 사이즈에 맞도록 중심을 기준으로 가장자리를 자르고 가져온다.
이것은 반복된 convolution으로 가장자리의 정보가 소실되어 이를 맞추기 위함이다.
이 과정을 반복하여 마지막 feature map을 생성할 때 1x1 convolution을 사용하여 channel이 2가 되도록 한다.
channel의 의미는 세포막과 세포에 대한 class이다.
down, upsampling할 때 주의할 점은 feature map의 사이즈가 홀수가 되지 않도록 하는 것이다.
만약 7x7이라면 사이즈를 반으로 줄일 때 3x3으로 할지 4x4로 할지 결정해야 되며 반대로 3x3을 upsampling할 때 7x7로 할지 6x6으로 해야할지 결정해야 된다.
그래서 모든 feature map의 사이즈를 짝수로 맞췄다.
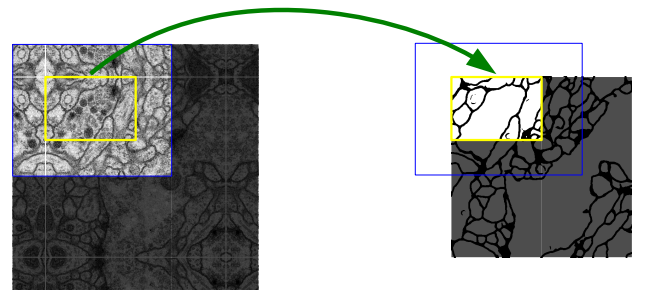
정확하게 이해가 안되는 부분이 있다.
입력 이미지와 출력 feature map의 사이즈가 일치하지 않는다.
반복해서 말하면 convolution을 할 때 padding을 사용하지 않았기 때문이다.
그래서 어떻게 예측을 하지? 라고 생각했다.
위 그림의 왼쪽에서 파란색 상자를 자세히 보면 가장자리가 노란색 상자를 기준으로 대칭이 된 것을 확인할 수 있다.
즉, convolution으로 인해 소실된 가장자리를 overlap-tile이라는 방법으로 interpolation하고 있다.
그럼 이 방법을 어디에 사용할까?
나는 network의 출력이 입력의 사이즈와 맞지 않으므로 이때 사용할 것이라 생각한다.
이 논문의 중요한 contribution은 contracting path에서 얻은 feature map을 expanding path에 전달함으로써 layer가 깊어질수록 잃어버린 spatial information을 보충하고 resolution을 점점 높여가는 중에 잃어버리는 context information을 잘 전달했다는 것이다.
DeepLab v1
나중에 추가…
CRF(Conditional Random Field)
나중에 추가…
DeepLab v3
나중에 추가…
image classification
어제에 이어서 이미지 분류 모델을 배웠다.
GoogleNet, ResNet, DenseNet, SENet, EfficientNet, Deformable convolution을 배웠다.
이 중 GoogleNet, ResNet, DenseNet은 이전에 배웠던 내용이므로 여기에 정리하지 않았다.
SENet
나중에 추가…
EfficientNet
나중에 추가…
Deformable convolution
나중에 추가…