semantic segmentation
이전 글에서 많은 내용을 배웠다.
여기서는 이전에 다루지 못한 내용을 적을 것이다.
upsampling
이미지에서 downsampling은 입력의 사이즈를 줄이는 것을 말한다.
예를 들어 14x14 이미지를 2x2 pooling layer로 7x7로 줄일 수 있다.
convolutional layer에 stride를 2로 해도 역시 사이즈를 줄일 수 있다.
반대로 upsampling은 입력 사이즈를 늘리는 것을 말한다.
 1
1
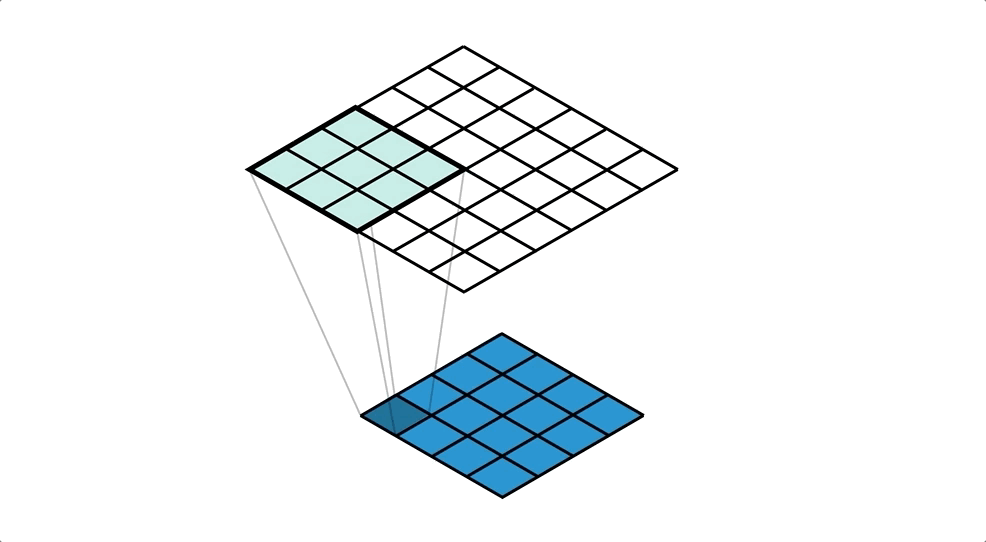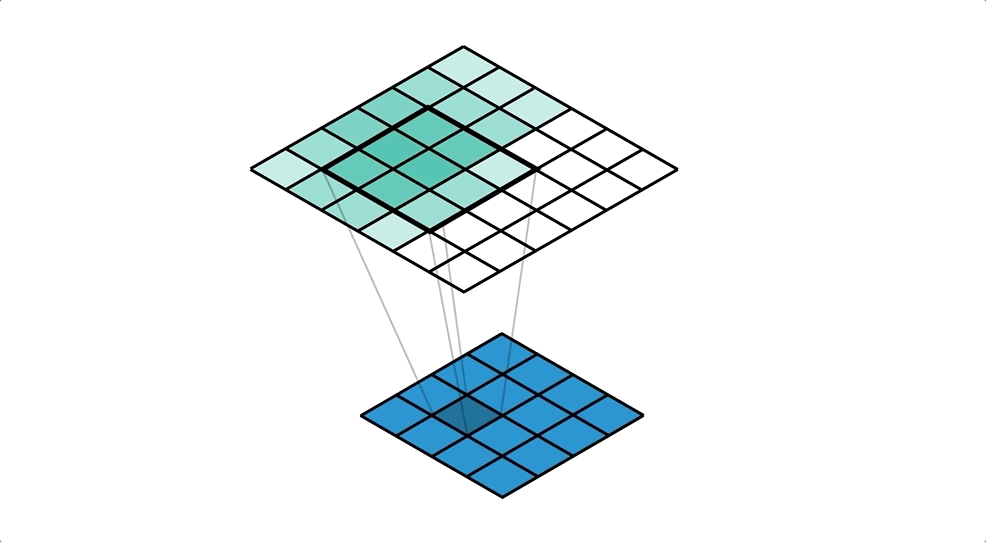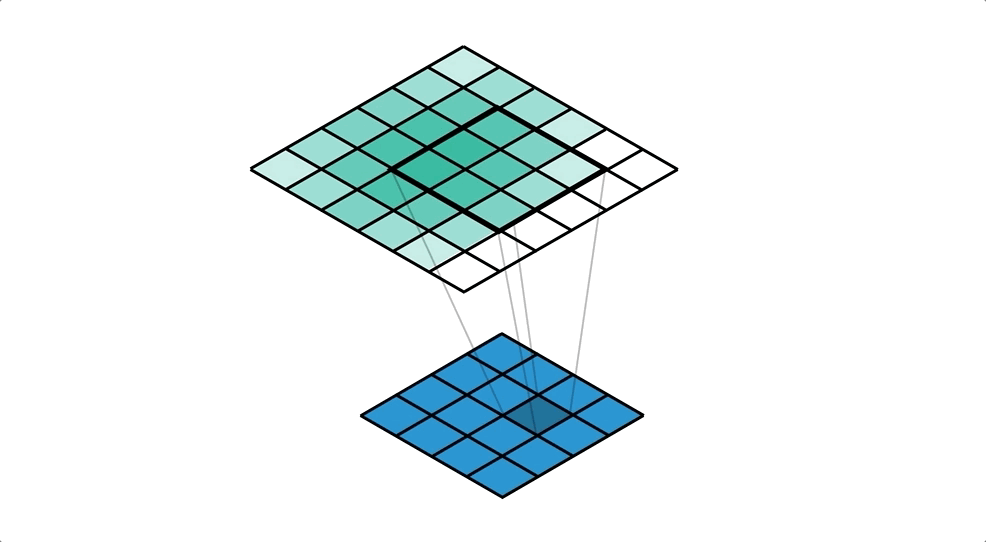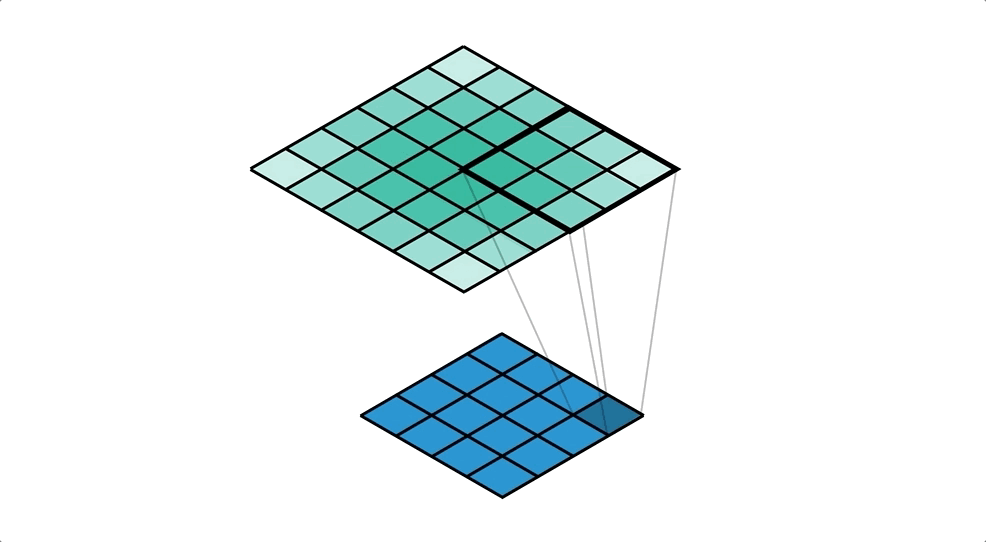
위 이미지는 upsampling을 설명하고 있다.
여기서는 4x4 행렬이 입력이고 6x6 행렬이 출력이며 3x3 kernel을 사용하고 있다.
입력 행렬의 하나의 값과 kernel과 곱한 값들을 출력으로 사용하고 있다.
옆으로 한칸 이동하여 위와 같은 작업을 반복한다.
이 작업을 하면 겹치는 부분이 있는데 이 부분들은 누적해서 더해준다.
위 이미지를 자세히 보면 겹치는 부분이 있는데 색이 점점 진해진다.
upsampling을 알아보면서 헷갈리는 것은 upsampling, deconvolution, transposed convolution이 모두 동일한 의미로 쓰인다는 것이다.
이는 모두 입력의 크기를 늘리는 연산이지만 pytorch에서는 방법이 다르다.
위 이미지는 transposed convolution이다.
torch.nn.Upsampling은 trainable parameter가 필요하지 않다.
하지만 torch.nn.ConvTranspose2d는 parameter가 있다.
deconvolution은 convolution의 역연산 이라는 의미이지만 엄밀하게 말하면 잘못된 표현이다.
하지만 관습적으로 사용하고 있어서 deconvolution을 한다고 하면 입력의 크기를 늘린다고 이해하면 된다.
transposed convolution
그럼 왜 transposed convolution인지 좀 더 알아본다.
이 부분은 이 글을 참고하였다.
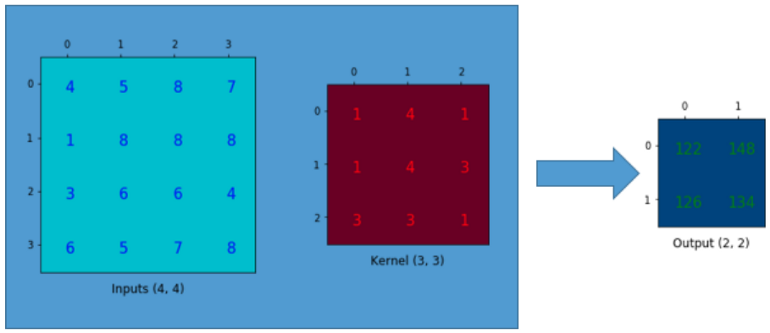
위 그림에서 입력은 4x4 행렬, kernel은 3x3 행렬이고 2x2 행렬이 출력이다.
convolution 연산을 행렬 곱으로 표현하면 다음과 같다.
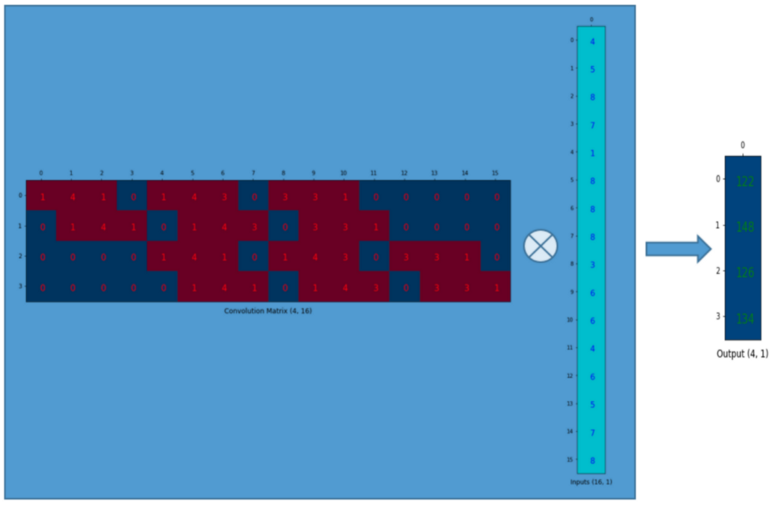
3x3 kernel은 위와 같이 4x16 행렬로 바꿀 수 있고 입력은 2D array에서 1D array로 바꿀 수 있다.
4x16 convolution matrix를 transpose 하여 행렬 곱을 하면 upsampling에서 봤던 transposed convolution 연산과 동일하게 된다.
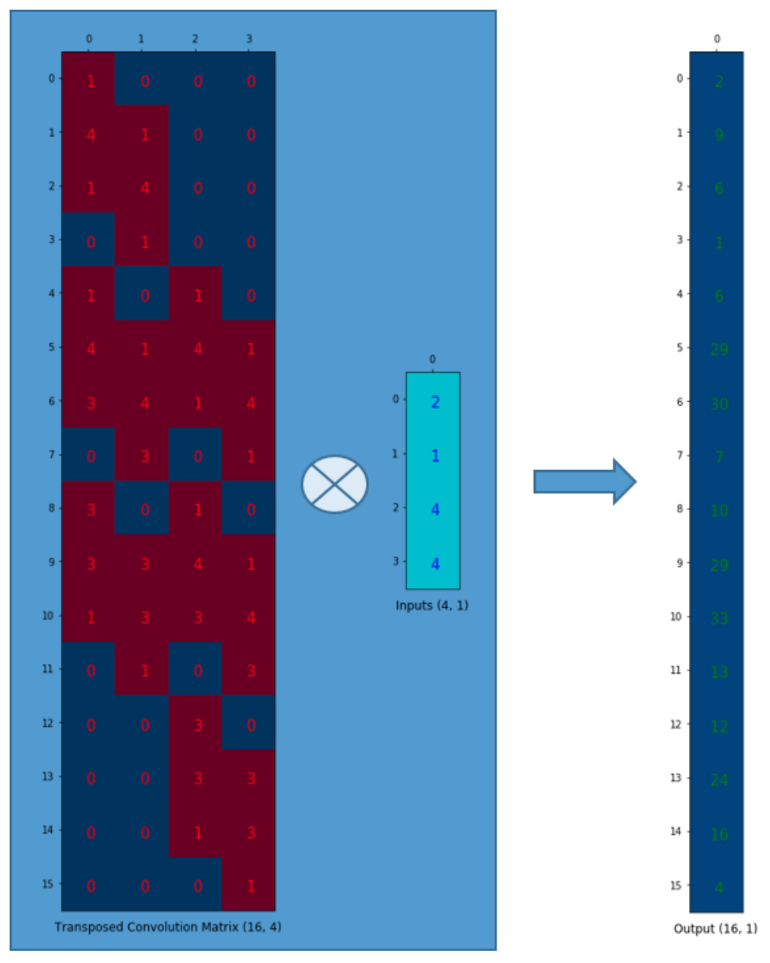
metric
semantic segmentation에서 사용하는 metric을 살펴본다.
pixel accuracy
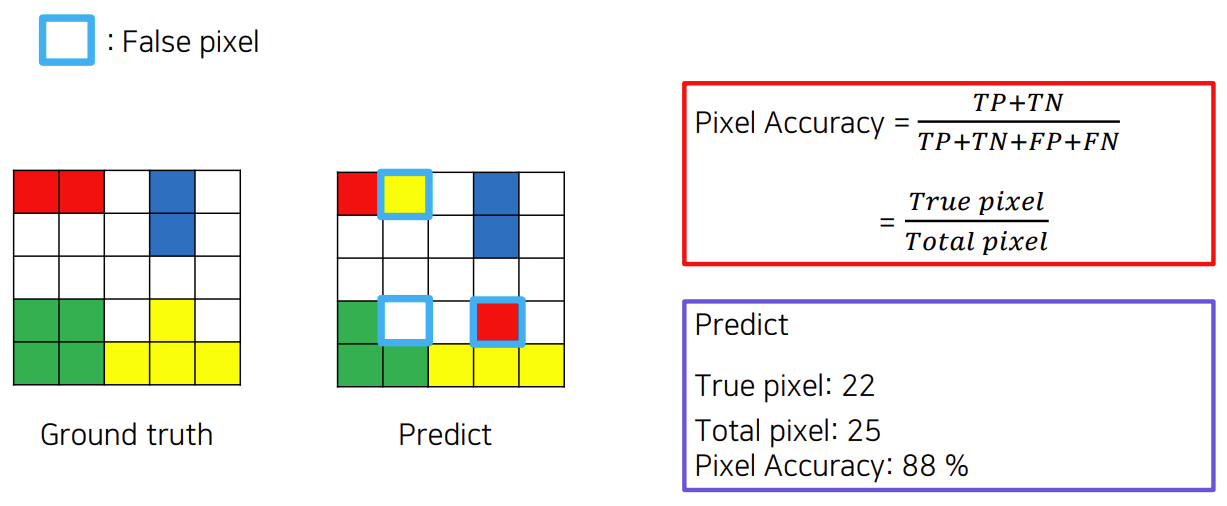
단순하게 전체 픽셀 중 실제 class와 예측 class가 동일한 픽셀을 나타낸다.
mean IoU
IoU는 이 글에서 설명했다.
여기서는 class가 여러 개이므로 mean IoU는 각 class의 IoU의 평균을 말한다.
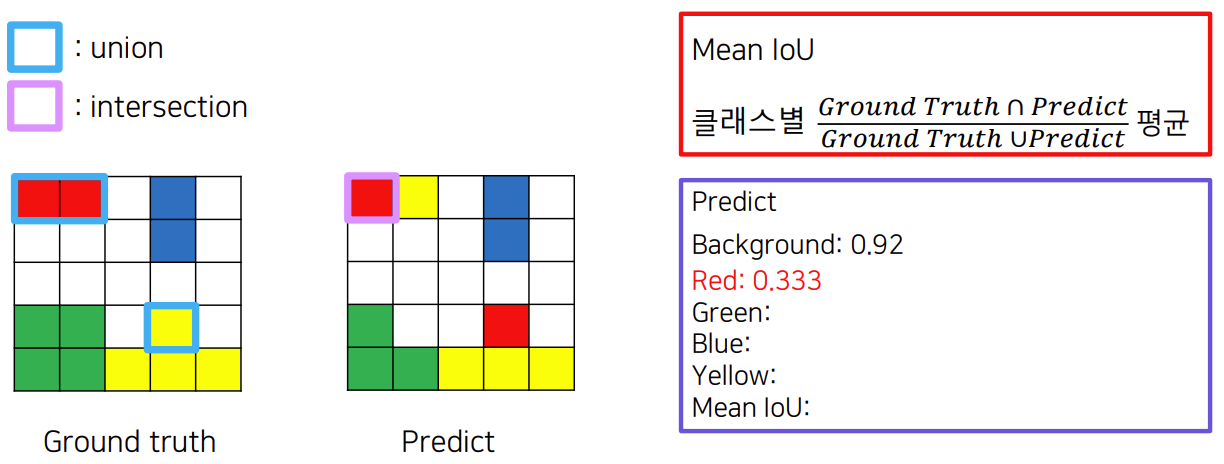
위 이미지를 보면 붉은색 class의 IoU는 Ground truth와 prediction의 합집합의 크기가 3이고 교집합의 크기가 1이므로 1 / 3이다.
비슷하게 초록색 class의 IoU는 3 / 4가 된다.
이들 IoU의 평균을 구하면 된다.
mAP(mean Average Precision)
나중에 추가…