convolution network
앞서 convolution layer에 대해 설명했다.
그 외 부가적인 내용을 설명하겠다.
fully connected layer는 점점 줄어드는 추세이다.
왜냐하면 parameter 수가 급격히 증가하여 generalization이 감소하게 된다.
convolution layer를 깊게 쌓고 fully connected layer를 줄이는 모델이 많이 보인다.
kernel의 width, height를 홀수로 사용하는 이유는 이미지 왜곡을 방지함이다.1
다음은 출력 데이터의 width를 계산하는 식이다.
\(w_{out} = w_{in} - k + 1 + 2*p,\\
w_{out}: 출력의\ width\\
w_{in}: 입력의\ width\\
k: kernel의\ width\\
p: padding\)
입력과 출력의 width가 동일할때 $p$를 구하면 $p = \frac{k-1}{2}$ 가 된다.
만약 kernel의 width가 짝수이면 p는 소수점이 생긴다.
이는 입력 데이터 양쪽에 똑같은 padding을 줄 수 없어서 왜곡이 된다.
사실 비대칭이 되어도 학습하는데 큰 영향은 없지만 전통적으로 홀수로 사용해왔다.
그래서 홀수를 권장한다.
1x1 convolutional layer
1x1 convolutional layer kernel의 width와 height는 각각 1, 1이다.
보통 kernel은 입력 값의 spatial information을 얻지만 이 경우는 그렇지 못한다.
그럼 왜 사용할까?
이 layer는 channel 수를 줄이기 위해 사용된다.
예를 들어 3x3 convolutional layer로 11 x 11 x 256인 입력 값을 11 x 11 x 128로 만드려고 한다(padding=1).
이때 필요한 parameter의 수는 3 x 3 x 256 x 128 = 294,912이다.
하지만 1x1 convolutional layer를 이용하면 1 x 1 x 256 x 128 = 32,768로 감소한다.
1x1 layer를 추가함으로서 network의 depth는 증가하지만 오히려 parameter의 수는 감소한다.
AlexNet
network가 두개로 나뉘었다.
당시 존재하던 gpu의 memory가 부족하여 2개의 gpu로 나누어 학습했다.
첫번째 convolutional layer에서 11x11 kernel을 사용했는데, 지금와서 보면 좋지 않은 선택이다.
일단 kernel의 width, height가 크면 parameter가 증가한다.
예를 들어 padding 없이 48x48인 입력 데이터에 대해 5x5 convolutional layer를 통과시킨다면 44x44가 출력된다.
하지만 3x3 layer를 한번 통과시키면 46x46이 되고 두번 통과시키면 44x44가 된다.
즉, 5x5 kernel이 보는 영역과 3x3 kernel 두번이 보는 영역이 같다.
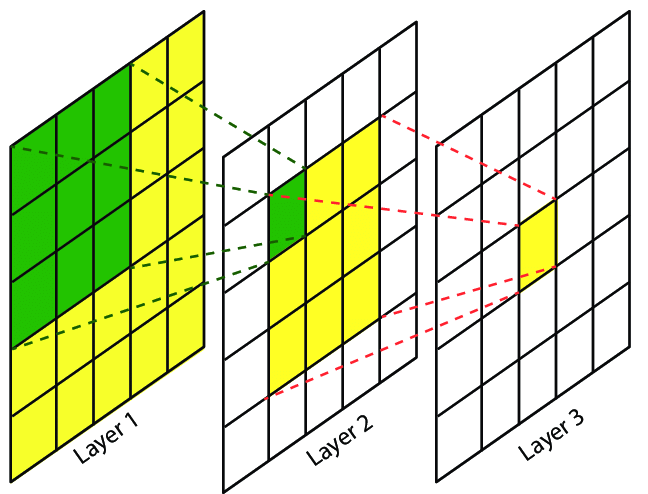 2
2
위 그림에서 5x5 kernel을 사용할때
Layer 1의 모든 값이Layer 3의 1x1=1개의 값에 대응한다.
3x3 kernel로Layer 1의 모든 값이Layer 2의 3x3=9개의 값에 대응한다.
비슷하게 3x3 kernel로Layer 2의 모든 값이Layer 3의 1x1=1개의 값에 대응한다.
따라서 width, height가 큰 kernel을 쓰는 것보다 3x3, 5x5, 7x7 kernel 여러개 사용하는 것이 parameter 수를 줄일 수 있다.
이 논문에서 최초로 activation function인 ReLU를 사용했다.
ReLU는 gradient를 보존하는 특징이 있어서 gradient vanishing 문제 해결에 도움을 주었다.
이전까지는 activation function의 의미는 non-linearity를 주기 위함이었다.
googLeNet
NIN(Network In Network), network 안에 network, 구조를 가진 inception block이 등장하였다.
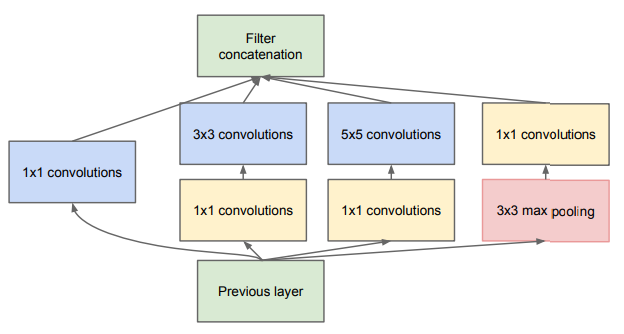 3
3
inception block에서 중요한 점은 3x3, 5x5 kernel을 적용하기 전에 1x1 kernel을 통과시켜 channel의 수를 줄였다.
또한 4갈래의 kernel을 적용한 결과 값을 concatenation하여 더 좋은 feature를 얻을 수 있었다.
ResNet
not yet
DenseNet
not yet
-
BoostCamp-ai-tech 질문 게시판 ↩