gradient descent
optimization
Mathematical optimization (alternatively spelled optimisation) or mathematical programming is the selection of a best element (with regard to some criterion) from some set of available alternatives.1
최적화(optimization)는 특정 집합에서 몇가지 기준을 가지고 최고의 요소를 선택하는 것이다.
보통 최대, 최소인 요소를 찾는다.
모델을 학습 데이터에 대해 최적화를 한다는 것은 데이터를 잘 설명하도록 parameter를 반복적으로 수정해 나가는 것이다.
최적화에 대한 몇가지 중요한 개념을 소개한다.
generalization
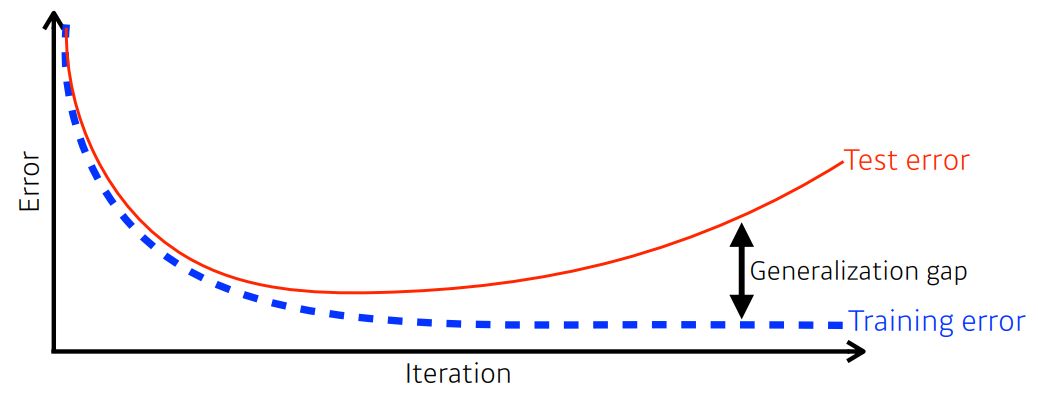
학습 데이터에 최적화를 할수록 예측 값과 실제 값의 차이가 감소한다.
하지만 테스트 데이터의 예측 값과 실제 값의 차이는 점점 증가한다.
학습 데이터에 대한 오차와 테스트 데이터에 대한 오차를 비교했을때 작으면 일반화(generalization)가 잘되는 모델이다.
즉, 어떤 데이터를 가져와도 학습 데이터의 결과만큼 좋다는 뜻이다.
일반화가 잘 안되는 경우는 두 데이터의 오차의 차이가 크다.
이것은 모델이 학습 데이터의 특징을 전부 다 학습했기 때문에 이 데이터와 약간 다른 값이 입력으로 들어오면 큰 차이를 발생시킨다.
혹은 학습 데이터에 내재되어 있는 오차(noise)까지 학습했기 때문에 테스트 데이터에 대한 성능이 좋게 나오지 못한다.
overfitting, underfitting
In statistics, overfitting is “the production of an analysis that corresponds too closely or exactly to a particular set of data, and may therefore fail to fit additional data or predict future observations reliably”.
Underfitting occurs when a statistical model cannot adequately capture the underlying structure of the data.
An under-fitted model is a model where some parameters or terms that would appear in a correctly specified model are missing.
Under-fitting would occur, for example, when fitting a linear model to non-linear data.
Such a model will tend to have poor predictive performance.2
과적합(overfitting)은 과하게 학습한다는 의미로 데이터에 과하게 학습이 되어 향후 미래의 데이터를 예측하는데 잘 하지 못하는 현상을 말한다.
과소적합(underfitting)은 데이터의 특징(혹은 패턴)을 적절하게 학습하지 못한 현상을 말한다.
예를 들어 비선형 데이터에 선형모델을 학습할 경우 예측 성능이 안좋은 경향이 보인다.
cross validation
교차검증(cross validation)은 테스트 데이터에 얼마나 일반화가 될 것인지 모델 평가하는 방법이다.
데이터가 많으면 다양한 특징을 가질 수 있으며 일반화된 모델로 학습될 가능성이 높다.
이런 경우 학습 데이터 대비 테스트 데이터의 성능을 비교하여 일반화 여부를 판단할 수 있을 것이다.
하지만 학습 데이터가 적은 경우 과적합이 발생할 가능성이 높다.
여러 모델을 고려하고 그 중 일반화가 가장 좋은 모델을 선택하고 싶다.
다음은 교차검증 과정을 설명한다.
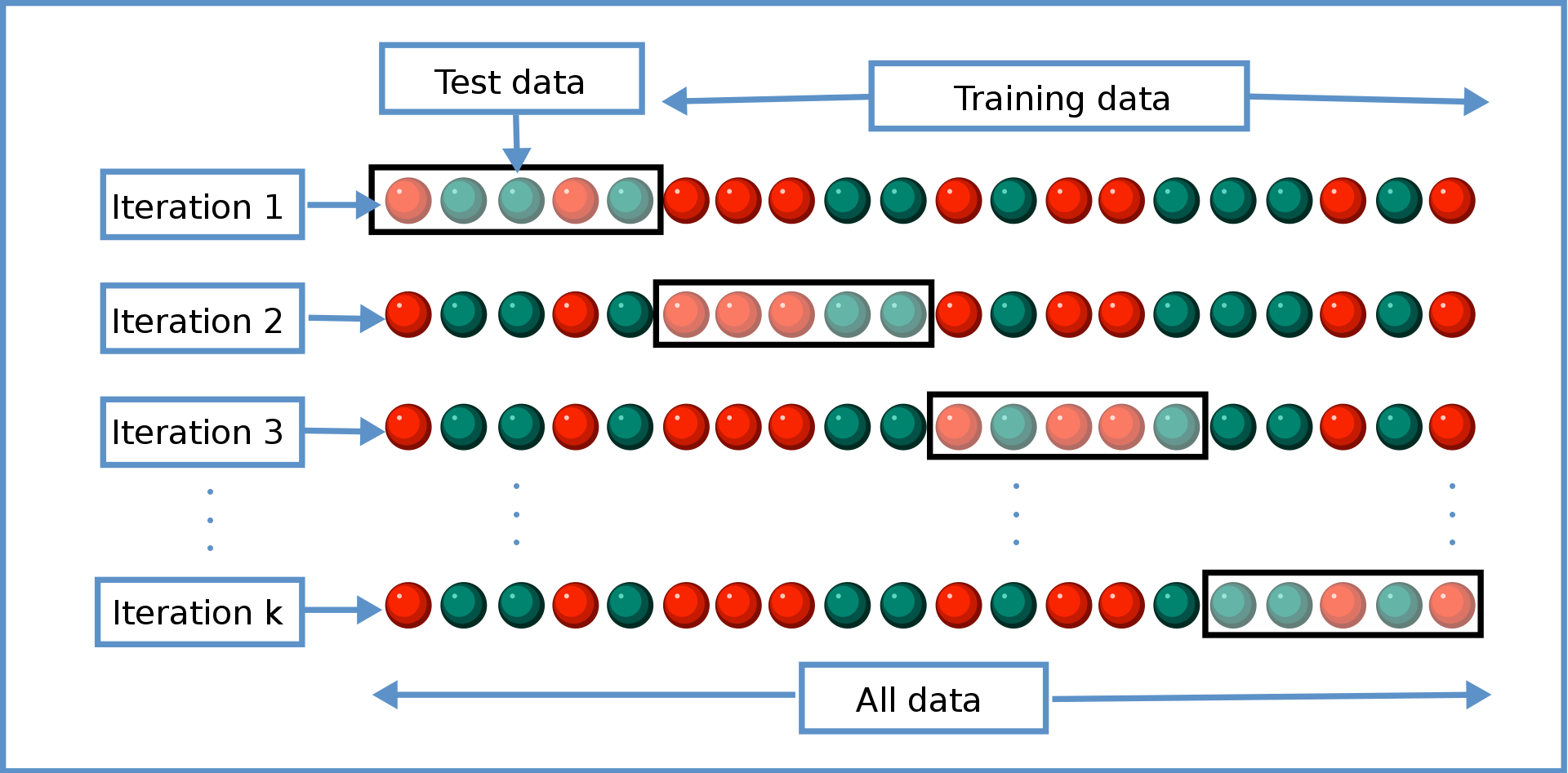 3
3
- 학습 데이터를 섞은 후 4개의 partition으로 나눈다.
- 1번 partition을 제외한 2, 3, 4번 partition으로 모델을 학습한다.
- 1번 partition으로 모델의 성능을 확인한다, 이때 모델의 성능을 평가하는 partition을 검정 데이터라 한다.
- 2번 partition을 제외한 1, 3, 4번 partition으로 모델을 학습한다.
- 2번 partition으로 모델의 성능을 확인한다.
- 3, 4번 partition도 위와 같이 진행한다.
- 각 partition에 대해 성능을 평가했고 이것들의 평균을 구한다.
- 다른 모델도 똑같이 하여 비교한다.
-
왜 검정 데이터가 따로 존재하는 걸까? 테스트 데이터를 사용하면 안되나?
우선 테스트 데이터는 모델 평가를 위해서만 사용해야 된다.
학습에 직, 간접적으로 영향을 주어선 안된다.
어떤 모델을 선택할 것인지, 예를 들어 선형회귀, SVM, random forest 등, learning-rate, batch-size 및 해당 모델에서 요구하는 hyper-parameter 등을 어떻게 선택하느냐에 따라 데이터에 대한 성능이 결정된다.
처음에는 heuristic search로 모델 및 hyper-parameter 선택을 하고 학습하여 검정 데이터로 성능을 살펴볼 것이다.
그리고 성능이 좋아지는 방향으로 계속 모델을 수정하며 계속 반복할 것이다.
검정 데이터의 성능이 좋아지도록 수정하는 것은 검정 데이터는 직접적으로 학습에 사용되지 않았지만 간접적으로 학습에 영향을 주는 것이다.
만약 이 과정에 테스트 데이터를 사용한다면 unseen data에 대해서 이와 똑같은 성능을 보장할 수 없다. -
왜 학습 데이터를 여러 개로 나누어서 일부분을 제외하고 모델을 학습시키는 과정을 반복할까?
학습과 검정 데이터를 어떻게 나누냐에 따라 모델의 성능이 결정될 것이다.
그래서 검정 데이터를 바꿔가면서 학습을 시키고 성능을 구하여 그의 평균을 보는게 바람직할 것이다.
이렇게 하면 결국 모든 학습 데이터를 다 사용하게 된다.
bias and variance 4
실제 값과 모델의 예측 값간의 차이가 있다.
이러한 차이는 편향(bias)와 분산(variance), 오차(error)로 분해할 수 있다.
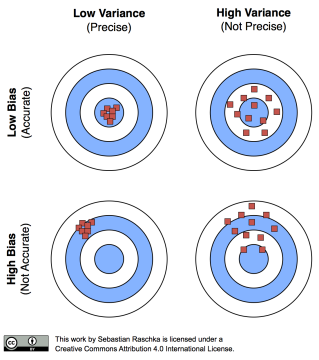 5
5
위 그림에서 빨간 점은 예측 값이다.
가장 좋은 경우는 왼쪽 위이다.
편향이 큰 경우는 모델이 데이터의 특징을 잘 학습하지 못하여 발생한다.
보통 이 경우를 과소적합(underfitting)이라 하며, 위 그림 왼쪽 아래와 같다.
데이터가 살짝 바뀌어도 값이 크게 변하지 않지만 대체적으로 모두 잘못된 값을 예측하고 있다.
분산이 큰 경우는 모델이 데이터의 특징을 너무 잘 학습하여 발생한다.
데이터에 내재된 noise까지 학습했기 때문이다.
보통 이 경우를 과적합(overfitting)이라 하며, 위 그림 오른쪽 위와 같다.
학습 데이터와 비슷할수록 성능이 좋지만 조금만 달라져도 예측이 크게 벗어난다.
분해
실제 데이터를 $D = (x_1, y_1), (x_2, y_2),\ …,\ (x_n, y_n)$ 이라 하자.
그럼 $x$ 와 $y$ 간 어떤 관계가 있다고 가정하며 $y = f(x) + \epsilon$ 이라 하자.
이때 $\epsilon$ 은 noise이며 $N(0, \sigma^2)$ 을 따른다.
우리는 $x$ 와 $y$ 의 관계를 잘 나타내는 함수 $f$ 를 찾는게 목표이다.
제곱 오차를 최소화하는 $f$ 에 근사한 함수를 $\hat{f}$ 라 하자.
이때 기대 제곱 오차는 편향, 분산, noise의 분산으로 분해할 수 있다.
\(E(y - \hat{f})^2 = E(y^2 + \hat{f}^2 -2y\hat{f})\\
\qquad = Var(y) + [E(y)]^2 + Var(\hat{f}) + [E(\hat{y})]^2 - 2yE(\hat{f})\\
\qquad = Var(y) + Var(\hat{f}) + (y - E(\hat{f}))^2,\ where\ E(y) = f\\
\qquad = \sigma^2 + Var(\hat{f}) + Bias(\hat{f})^2,\ where\ Var(y) = \sigma^2\)
여기서 $Var(\hat{f}), Bias(\hat{f})^2$ 를 줄일 수 있는 오차라 하며 모델을 통해 조절할 수 있다.
$\sigma^2$ 는 줄일 수 없는 오차라 하며 이는 데이터에 내재된 오차라 줄이기 힘들다.
여기서 이해 안되는 것은 $f$ 가 deterministic function이라서 $E(f) = f$ 가 성립한다는데 이해를 전혀 못하겠다…
좀 더 찾아봐야겠다…
bootstrapping
Bootstrapping is any test or metric that uses random sampling with replacement, and falls under the broader class of resampling methods.6
부트스트래핑(bootstrapping)은 복원 임의 추출하는 방법이며 resampling 방법 중 하나에 속한다.
bagging(bootstrapping aggregating)
부트스트래핑으로 여러 모델을 학습한다.
예를 들어 여러개의 선형회귀모델 혹은 분류모델을 학습시키고 결과값의 평균을 예측값으로 사용 혹은 다중투표를 한다.
특히 의사결정나무(decision tree)을 사용하면 성능이 좋다.
그래서 대표적인 모델로 랜덤 포레스트(random forest)가 있다.
장점은 하나의 성능이 좋지 않은 모델을 사용한 것 보다 우수한 결과를 보이며 덜 overfitting을 보인다.
데이터의 높은 분산에 영향이 적다.
단점은 데이터 크기가 크면 계산 비용이 커진다.
만약 데이터가 높은 편향을 가진다면 bagging 모델도 높은 편향을 가진다.
bagging은 여러 모델을 합치므로 결과에 대해 해석하기 힘들다.
bagging이 분산을 줄여주는 원리로 jensen inequality 사용. 이 부분 추가 할 것
boosting
추후 추가
stochastic, mini-batch, batch gradient descent
이전 글 에서 잠깐 언급했지만 정확하히는 stochastic gradient descent는 전체 데이터 중 단 하나의 데이터를 사용하여 gradient를 계산 후 업데이트 한다.
단 하나의 데이터만 사용하기 때문에 학습이 오래걸리고 데이터의 양에 따라 계산 비용이 커진다.
mini-batch gradient descent는 데이터의 일부분을 추출하여 gradient를 계산한다.
stochastic gradient descent보다 더 많은 데이터를 사용하기 때문에 계산비용이 적다.
batch gradient descent는 한번 학습할때 모든 데이터를 사용하여 gradient를 계산한다.
데이터가 커지면 out-of-memory가 발생할 수 있다.
그럼 batch size에 따라 성능이 달라질까?
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima 에 따르면 batch size가 크면 sharp minimizer에 수렴하고 크면 flat minimizer에 수렴한다고 나온다.
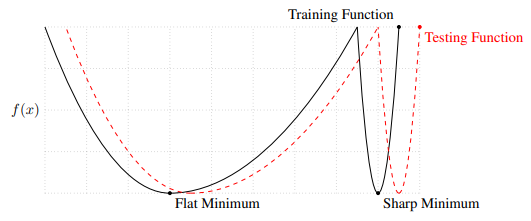 7
7
위 그림을 보자.
flat minimum에서 training function과 testing function을 비교하면 $f(x)$ 의 값의 차이가 작다.
sharp minimum에서 보면 training과 testing function의 값이 차이가 크다.
테스트 데이터가 학습 데이터와 약간 다르더라도 batch size가 작을때 안정적으로 예측을 할 수 있다.
하지만 batch size가 클때 테스트 데이터가 약간 다르면 예측 값이 크게 변한다.
이러한 내용을 이 논문 에서는 수치적으로 증명했다.
several optimizers
- momentum
- NAG(Nesterov accelerated gradient)
- Adagrad
- Adadelta
- RMSprop
- Adam
추후 추가
regularization
- early stopping
- parameter norm penalty
- data augmentation
- noise robustness
- label smoothing
- dropout
- batch normalization
추후 추가
optimizer practice
추후 추가
convolution
convolution의 수학적 의미는 kernel을 이용해 신호(signal)를 국소적으로 증폭 혹은 감소시켜서 정보를 추출 혹은 필터링하는 것이다.
다음은 수학적 정의다.
\(continuous: [f * g](x) = \int_{\mathbb{R}^d}f(z)g(x-z)dz = \int_{\mathbb{R}^d}f(x-z)g(z)dz = [g * f](x)\\
discrete: [f * g](i) = \sum_{a \in \mathbb{Z}^d}f(a)g(i-a) = \sum_{a \in \mathbb{Z}^d}f(i-a)g(a) = [g * f](i)\)
다음은 convolution 연산을 시각화한 것이다.
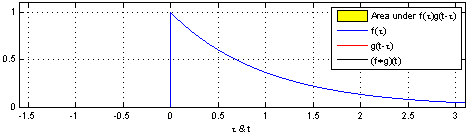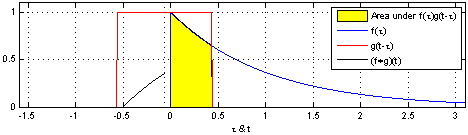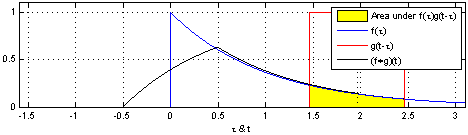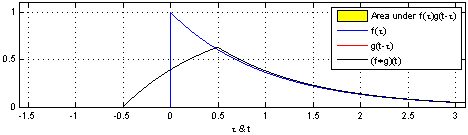 8
8
우리가 배운 MLP(Multiple Layer Perceptron)는 fully connected layer를 여러개 쌓은 network이다.
입력 데이터가 가중치 행렬에 의해 선형변환되고 편향이 더해진 후 비선형함수를 통과시켰다.
여기서 소개할 convolution 연산도 선형변환의 일종이다.
 9
9
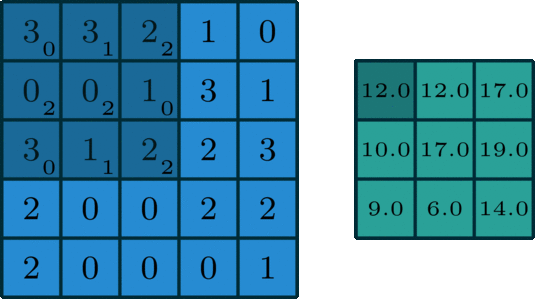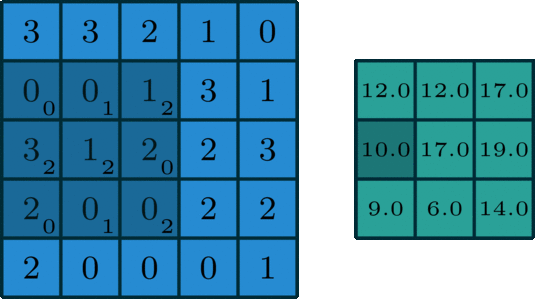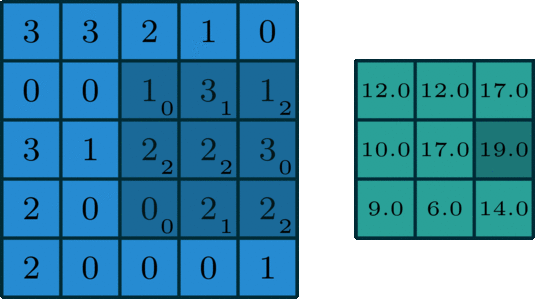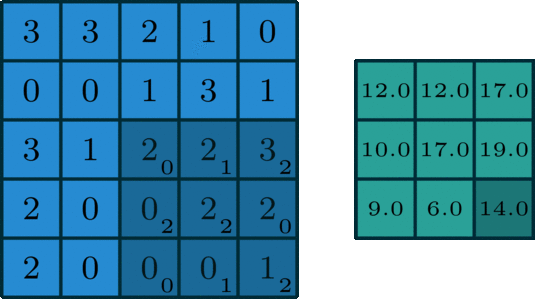
위 그림은 convolution 연산을 잘 설명하고 있다.
입력 데이터 5 x 5 행렬은 다음과 같다.
\(\begin{pmatrix}
3 & 3 & 2 & 1 & 0\\
0 & 0 & 1 & 3 & 1\\
3 & 1 & 2 & 2 & 3\\
2 & 0 & 0 & 2 & 2\\
2 & 0 & 0 & 0 & 1
\end{pmatrix}\)
kernel 혹은 filter 라 불리는 3 x 3 행렬이 다음과 같이 주어진다.
\(\begin{pmatrix}
0 & 1 & 2\\
2 & 2 & 0\\
0 & 1 & 2
\end{pmatrix}\)
kernel은 위 그림처럼 입력 데이터의 일부분과 계산을 하고 그 결과가 오른쪽 초록색 행렬에 대응된다.
예를 들어 초록색 행렬의 1행 1열의 값은 입력 데이터의 1~3행 & 1~3열은 다음과 같다.
\(\begin{pmatrix}
3 & 3 & 2\\
0 & 0 & 1\\
3 & 1 & 2
\end{pmatrix}\)
이 부분행렬과 kernel의 각 원소와 곱하고 더하면 0 * 3 + 1 * 3 + 2 * 2 + 2 * 0 + 2 * 0 + 0 * 1 + 0 * 3 + 1 * 1 + 2 * 2 = 12이다.
그럼 초록색 행렬의 1행 2열의 값은 kernel이 오른쪽으로 한칸 움직인 후 그에 대응하는 입력 데이터의 부분행렬과 위와 같이 계산하면 된다.
위와 같이 딥러닝에서 사용하는 convolution은 수학에서 말하는 convolution이 아니다.
좀 더 정확히는 cross-correlation이다.
kernel을 통과한 후 결과 행렬의 너비와 높이는 $(H - K_H + 1, W - K_W + 1),\ (K_H, K_W): height,\ width\ of\ kernel$ 이다.
입력 데이터가 2차원을 넘어설때, 즉 n x n 행렬이 여러개인 3차원 이상 행렬을 텐서(tensor)라 부른다.
3차원 텐서의 경우 각 차원의 의미를 보통 (channel, width, height) 혹은 (width, height, channel)로 나타낸다.
RGB의 경우 channel이 3개이고 흑백인 경우 1개이다.
앞서 살펴본 convolution은 2차원 행렬에 대한 연산이다.
텐서에 대한 convolution은 이와 비슷하다.
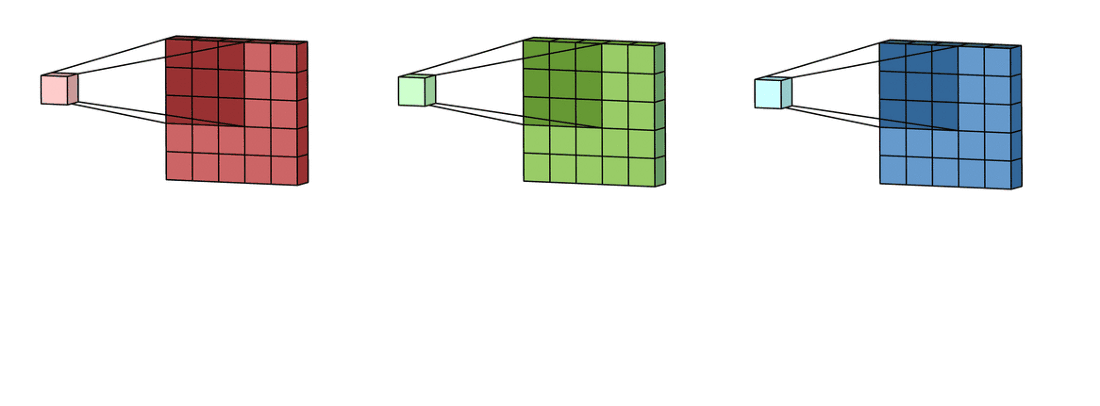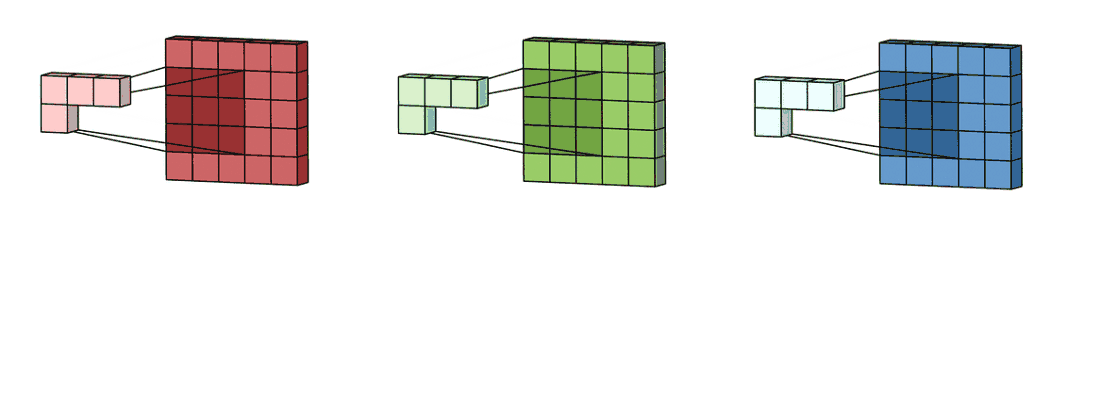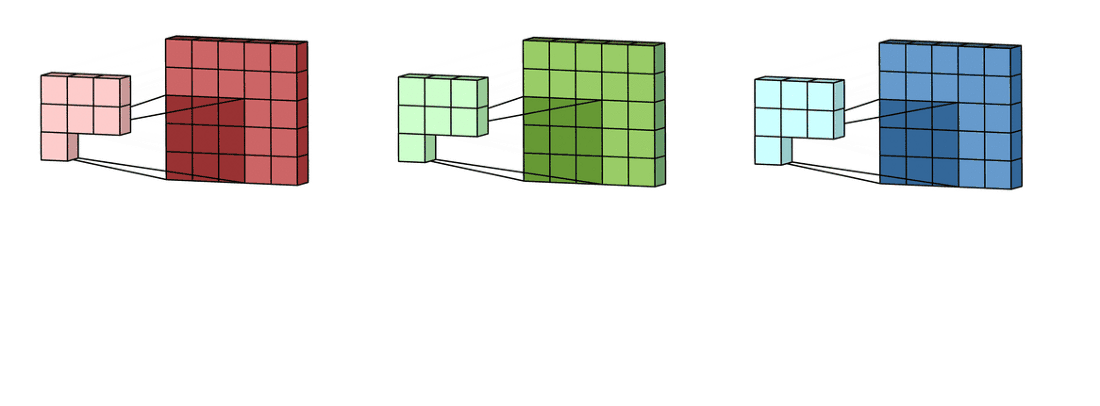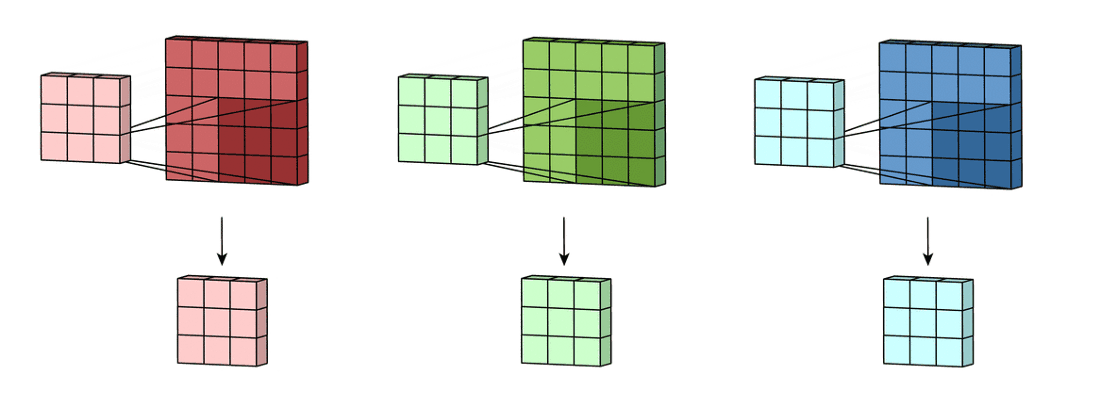 9
9
위 그림처럼 2차원 행렬이 3개인 경우에 대해 convolution 연산을 해보자.
먼저 각 2차원 행렬에 대해 convolution 연산을 한다.
 9
9
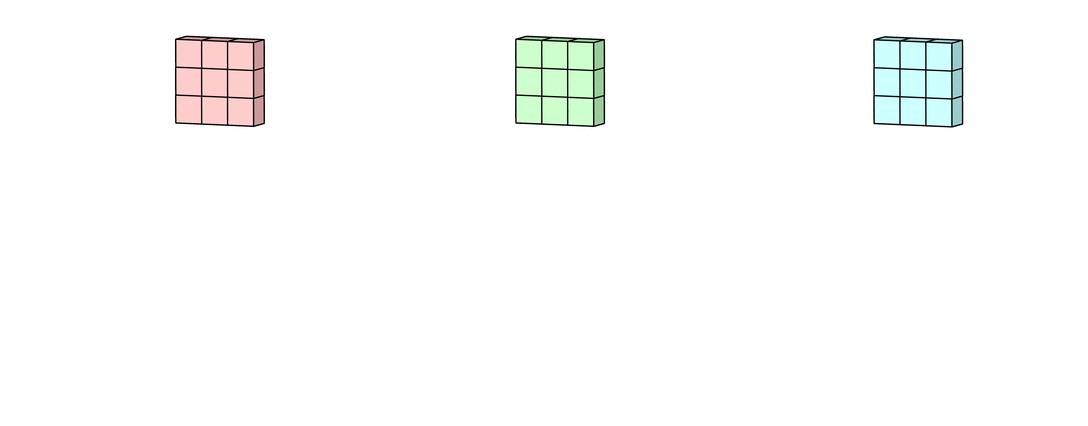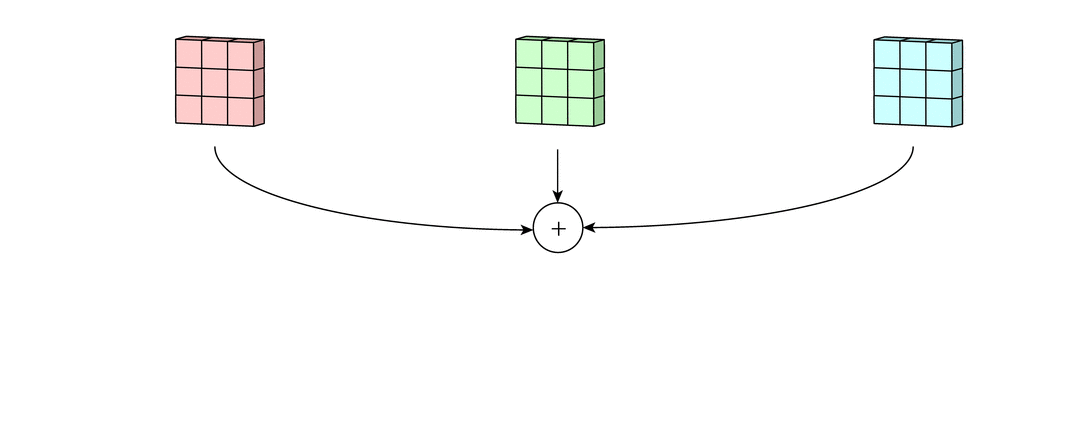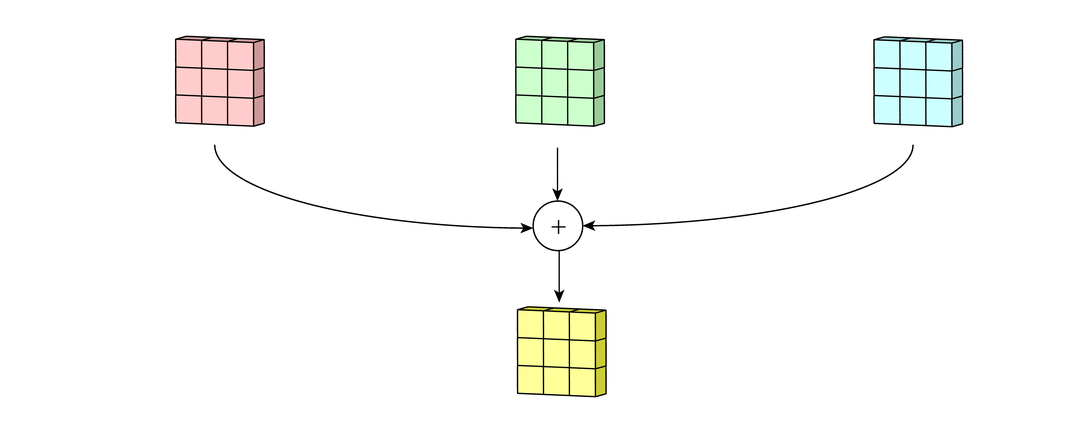
위 그림처럼 convolution의 결과를 같은 위치의 원소끼리 더하여 하나의 2차원 행렬로 만든다.
정리하면 3차원 텐서(c, W, H)에 대해 convolution 연산을 할때 kernel은 입력 데이터의 channel 갯수만큼 필요하다.
그리고 연산의 결과는 2차원 행렬이 된다.
이때 kernel의 차원은 $(c, K_W, K_H)$ 가 된다.
결과가 3차원 텐서(d, W, H)이길 바란다면 kernel의 차원은 $(c, K_W, K_H, d)$ 가 된다.
convolution example
kernel의 값에 따라 입력 데이터의 추출되는 특징이 달라진다.

여기 예시로 원본사진이 있다.
이 사진에 대해 여러 kernel을 적용한 결과를 살펴볼 것이다.
왼쪽은 3 x 3 kernel의 weight이고 오른쪽 사진은 kernel을 적용한 사진이다.
- blur

- left sobel

- top sobel

convolution backpropagation
나중에 추가…