여태까지 주어진 이미지로 18개의 class로 분류하는 모델을 만들었다.
학습이 잘 안되서 모든 과정을 처음부터 다시 하기로 생각했다.
assumption
학습 데이터로 2700명의 사진이 있고 각 사람마다 7개의 사진, 마스크 착용 5장, 미착용 1장, 오착용 1장,이 주어졌다.
분류할 것은 사진을 보고 성별, 나이대(~30세 미만, 30세 이상 60세 미만, 60세 이상), 착용, 미착용, 오착용이다.
미착용 사진은 마스크를 착용하지 않은 사진을 말하며 마스크 착용에 따라 정상적으로 착용, 오착용이 된다.
여기서 내가 세운 가정은 우리는 어떤 인물의 사진을 볼 때 성별과 나이대를 구분하기 쉬울 것이다. 이다.
얼굴을 볼 때 어떤 특정 부분만 보고 성별과 나이대를 추측하지 않고 전체적으로 본다.
그래서 어떤 모델을 먼저 성별과 나이대에 대한 특징을 학습시키고 나머지 데이터로 fine-tuning할 생각이다.
마스크를 착용한 상태에서는 나이대를 판단하기 어렵기 때문에 먼저 미착용 이미지로 학습하려고 한다.
모델을 여러 개 만들고 학습해서 분류하지 않는 이유는 데이터 안에 공통적인 특징을 공유하길 원하기 때문이다.
예를 들어 성별, 마스크 착용, 나이대 분류 모델을 각각 만들자.
성별 모델에서 추출한 특징은 나이대 모델에 적용할 수 없다.
두 모델 공통적으로 사람 형상이라는 특징을 공유할 수 있을 것이고 서로 도움이 될 수 있을 것이다.
그래서 따로 만들지 않고 한 모델을 만들어 학습할 것이다.
training
먼저 미착용 이미지로 성별과 나이대를 학습한다.
학습에 사용되는 이미지의 수는 2700개이다.
매우 적은 양이다.
그래서 data augmentation을 적용하여 학습 데이터를 늘려야 된다.
사용한 augmentation은 다음과 같다.
- CenterCrop(400, 256)
- (224, 224)
- RandomBrightnessContrast()
- HorizontalFlip()
- InvertImg()
- CoarseDropout(4, 50, 50)
임의의 50x50 영역 4개를 잘라낸다(cutout). - Normalize()
그 외 학습에 사용한 hyper-parameter들이다.
- epoch: 50
- batch size: 128
- fine-tuning: 1e-5
ImageNet으로 학습한 모델을 사용한다.
domain이 다르지만 객체에 대한 특징을 추출하는데 좀 더 효과적이다.
pre-trained weight를 그대로 사용하지 않고 현재 domain에 맞게 tuning이 필요하다.
이 값이 너무 크면 기존에 학습한 weight가 많이 변하기 때문에 작은 값을 사용했다. - learning rate: 6e-4
classifier를 학습하는데 사용하는 learning rate이다. - optimizer: Adam
- L2 regularization: 3e-5
- loss: label smoothing(0.1)
smoothing 값을 0.1을 사용했다.
loss는 label smoothing을 사용한다.
이 과정에서 분류할 class의 수는 6개로, 여성-30세 미만, 여성-30세 이상 60세 미만, 여성-60세 이상, 남성-30세 미만, 남성-30세 이상 60세 미만, 남성-60세 이상이다.
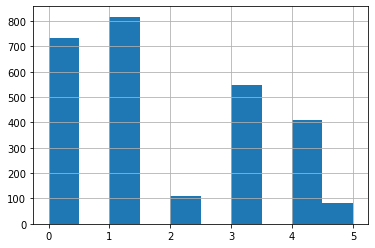
class 분포를 보면 남녀 60세 이상의 수가 적다.
위 그림을 보면 2와 5에 해당하는 경우가 여성-60세 이상, 남성-60세 이상이다.
imbalanced class의 경우 학습이 잘 안되어서 cross entropy 보다 과적합을 피할 것으로 기대된다.
모델은 ResNet을 사용한다.
복잡한 모델을 사용하여 좋은 성능을 얻을 수 있으나 학습하는 시간이 오래걸리고 layer가 많아서 모델이 잘 학습하는지 확인하기 어렵다.
grad CAM을 사용하여 layer별로 잘 학습이 되는지 확인할 예정이다.
학습은 5-fold cross validation으로 평가한다.
평균 validation accuracy, f1 score를 보고 얼마나 일반화가 되었는지 판단한다.
다음은 ResNet18, ResNet34, ResNet50, ResNet101을 사용하였으며 각각 train loss, accuracy, f1 score와 validation loss, accuracy, f1 score를 나타낸다.
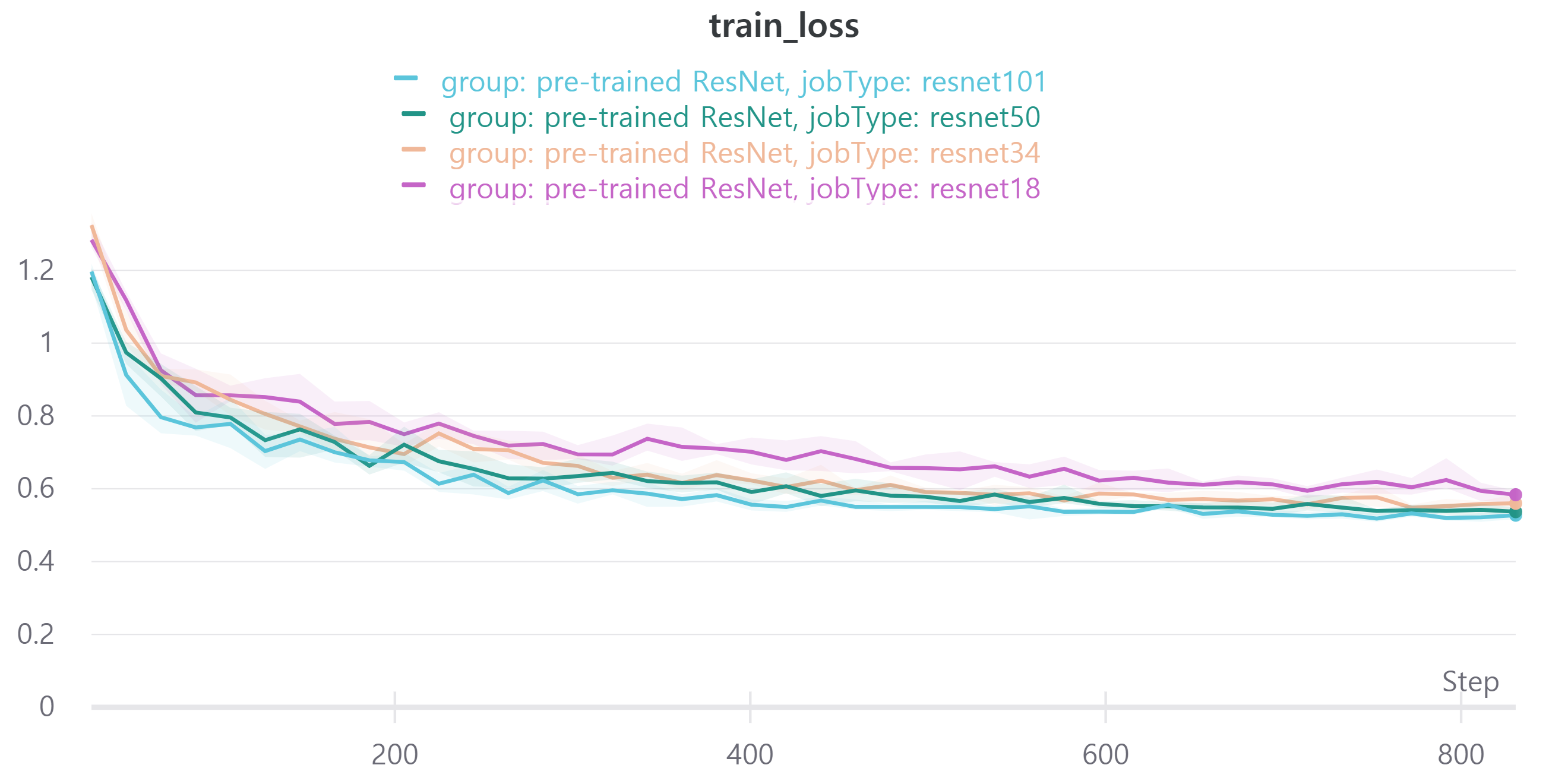
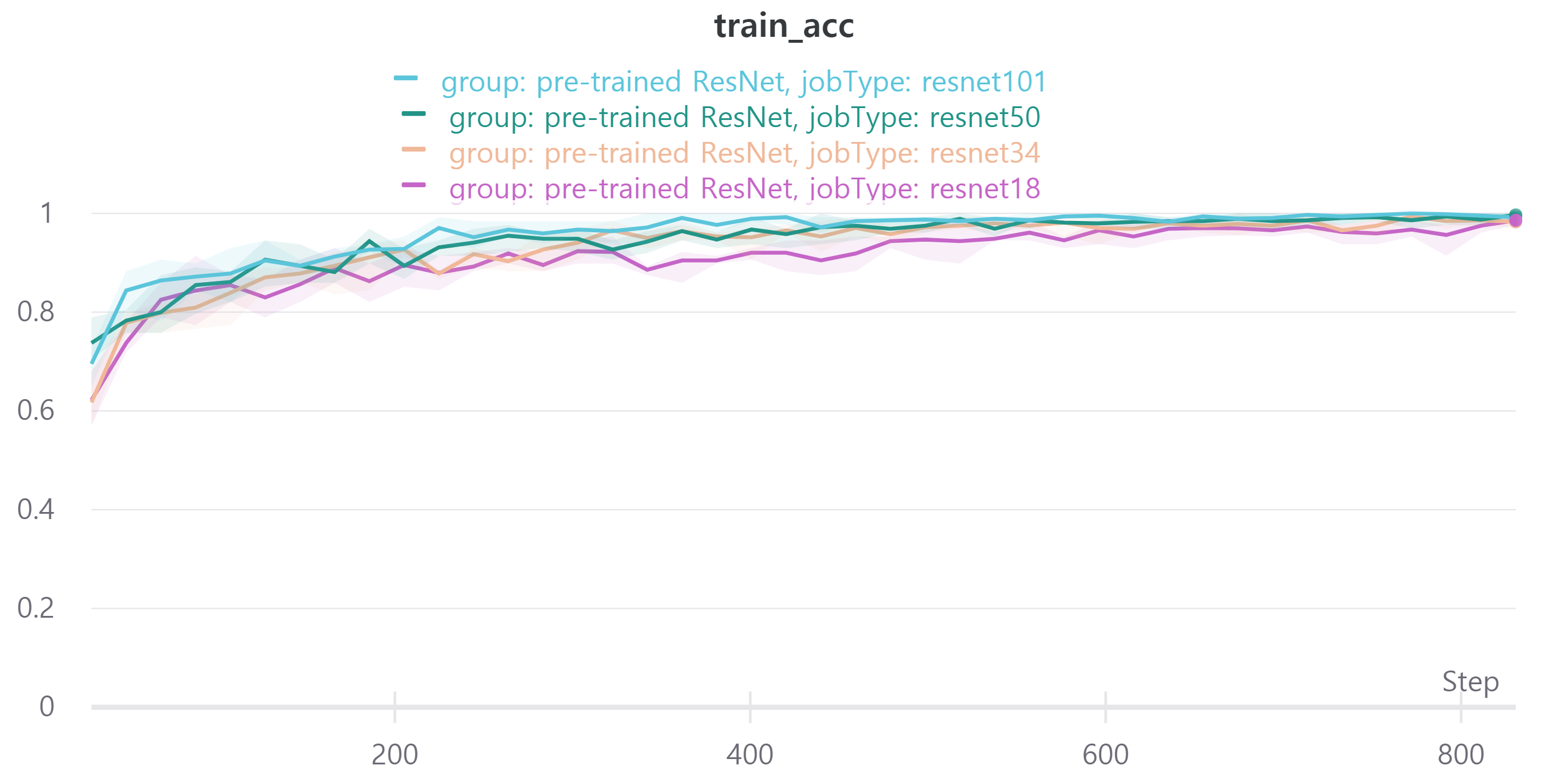
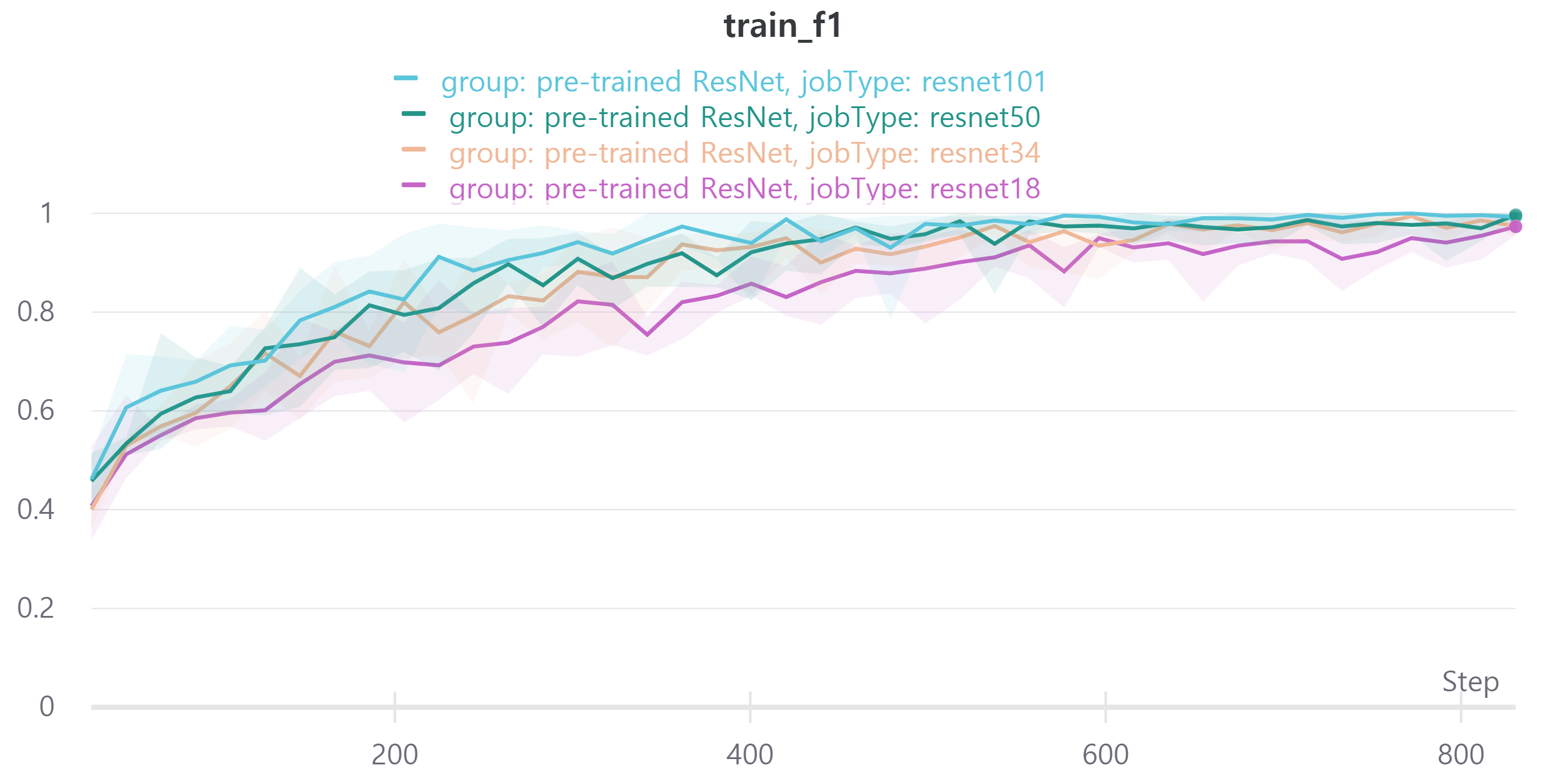
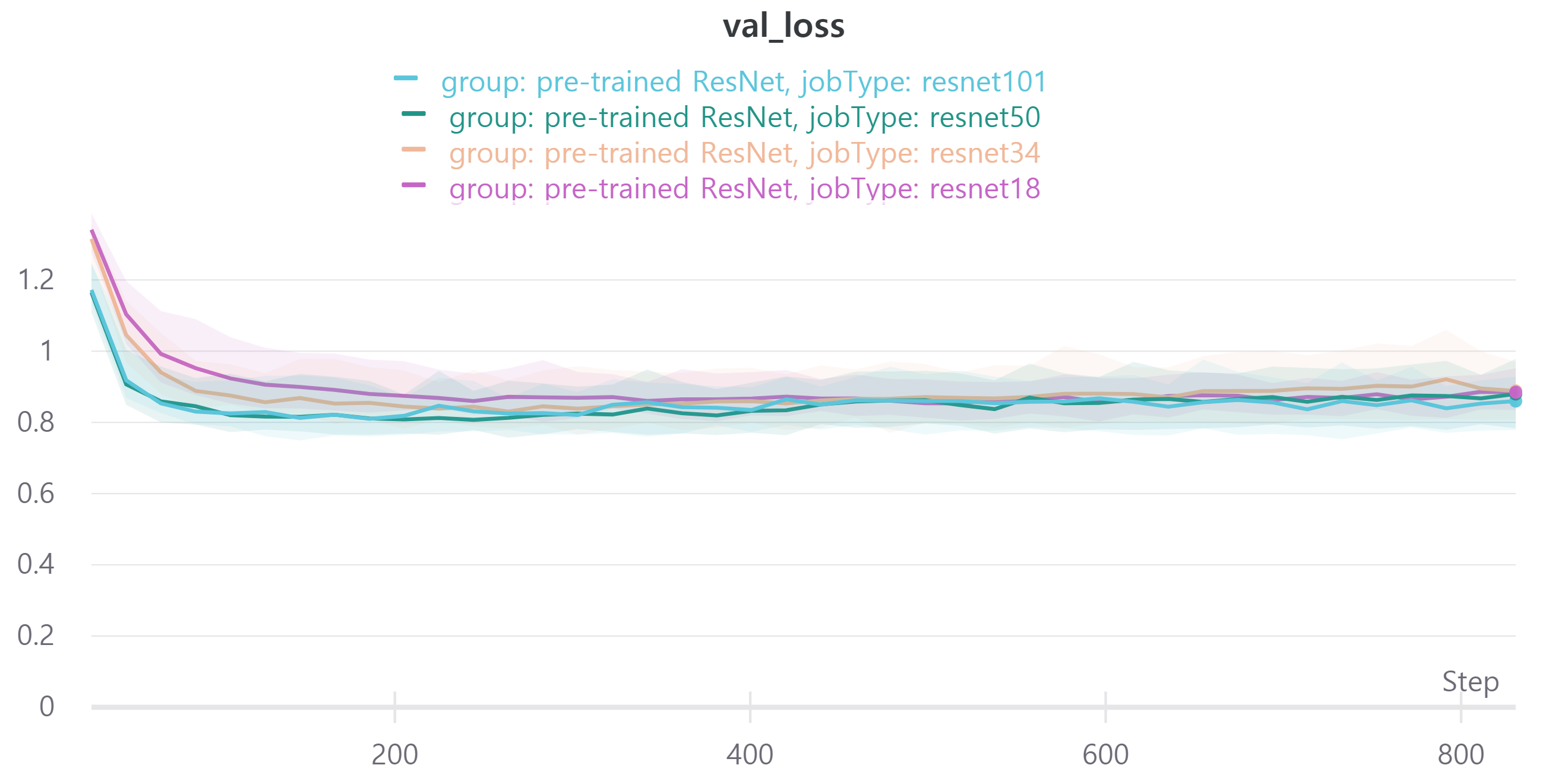
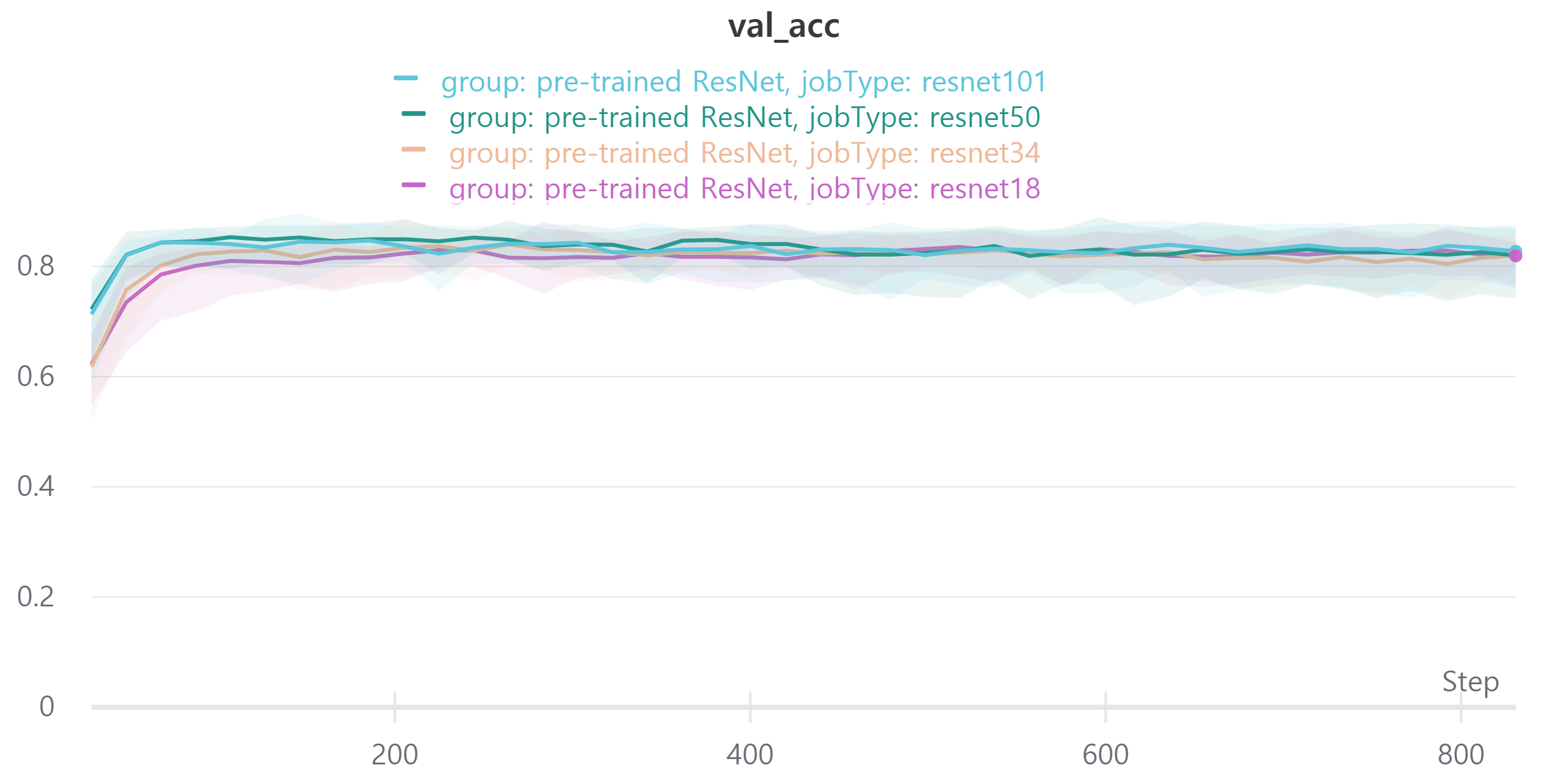
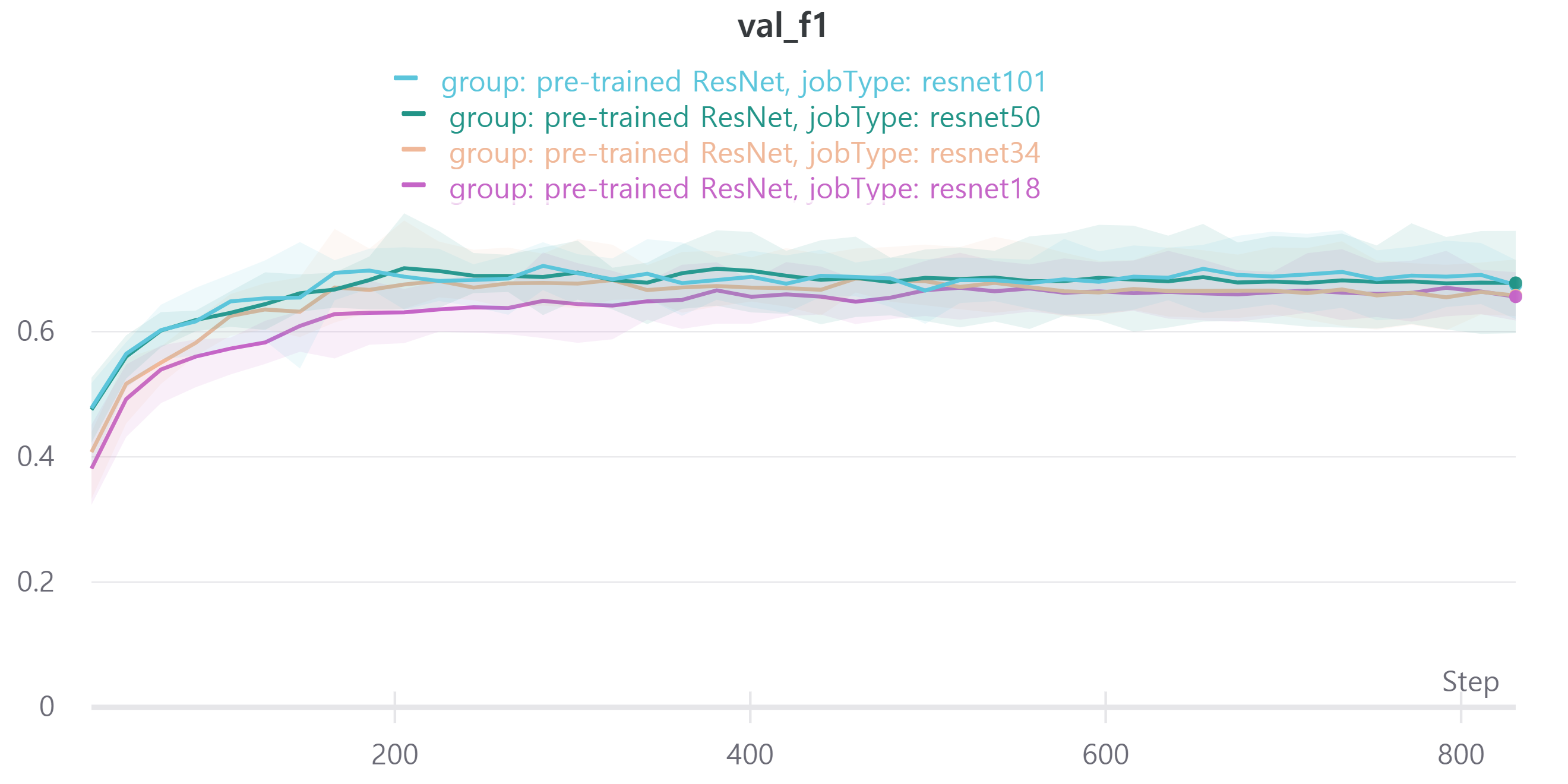
validation f1 score를 보면 ResNet18과 ResNet34, ResNet50, ResNet101이 비슷한 성능을 보인다.
adam + sgd + cosine scheduler
adam은 빠르게 수렴하는 특징이 있다.
sgd는 adam에 비해 수렴하는 속도가 느리지만 일반화 정도가 높다고 알려져 있다.
그래서 처음은 adam으로 학습하고 나중은 sgd로 학습하는 경우가 있다고 한다.
다음은 adam epoch 15, sgd epoch 50으로 학습하였고 adam으로만 학습한 경우와 비교하였다.
두 경우 모두 ResNet18을 사용하였고 optimizer와 epoch만 차이가 있고 나머지는 동일하다.
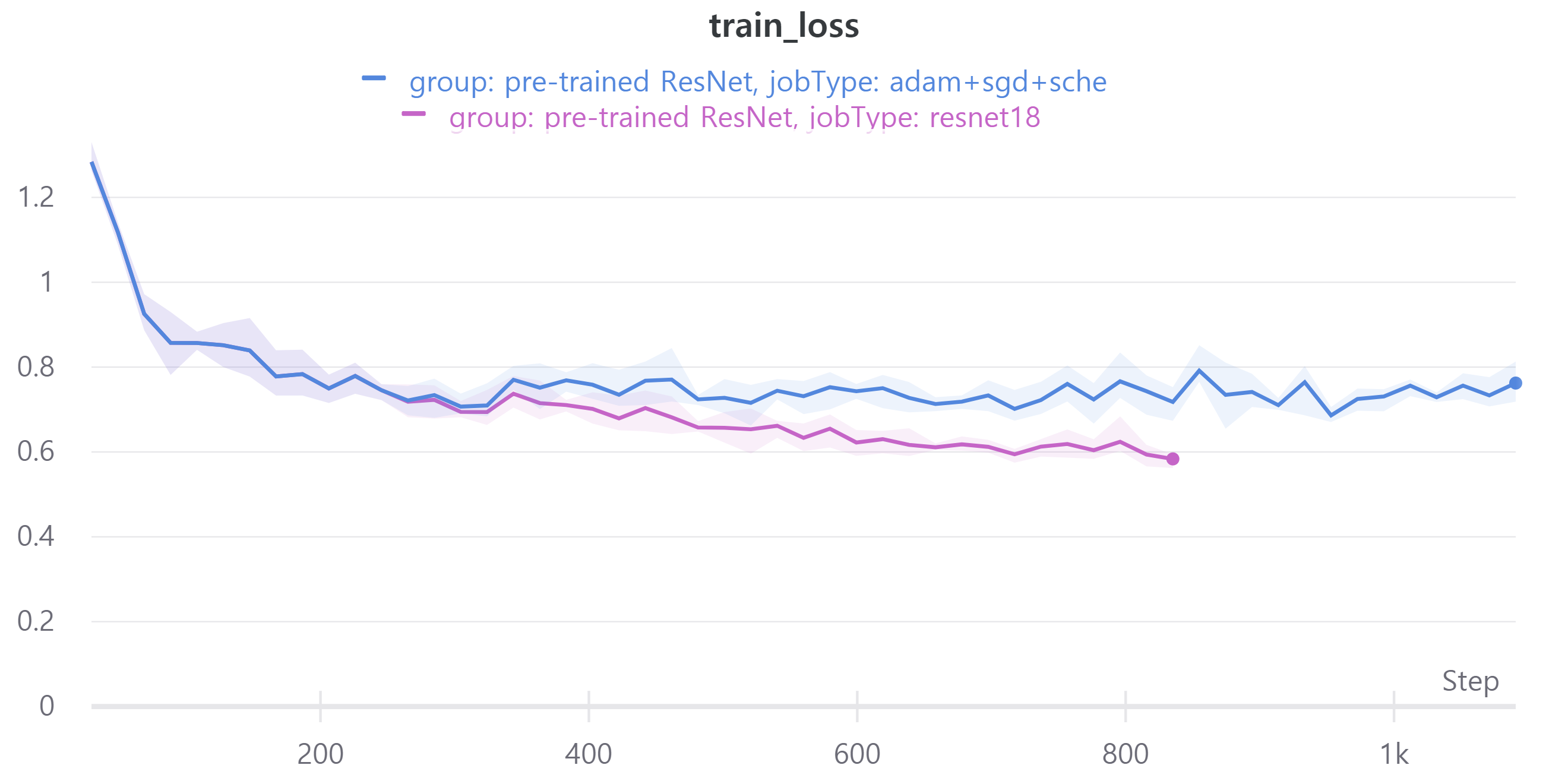
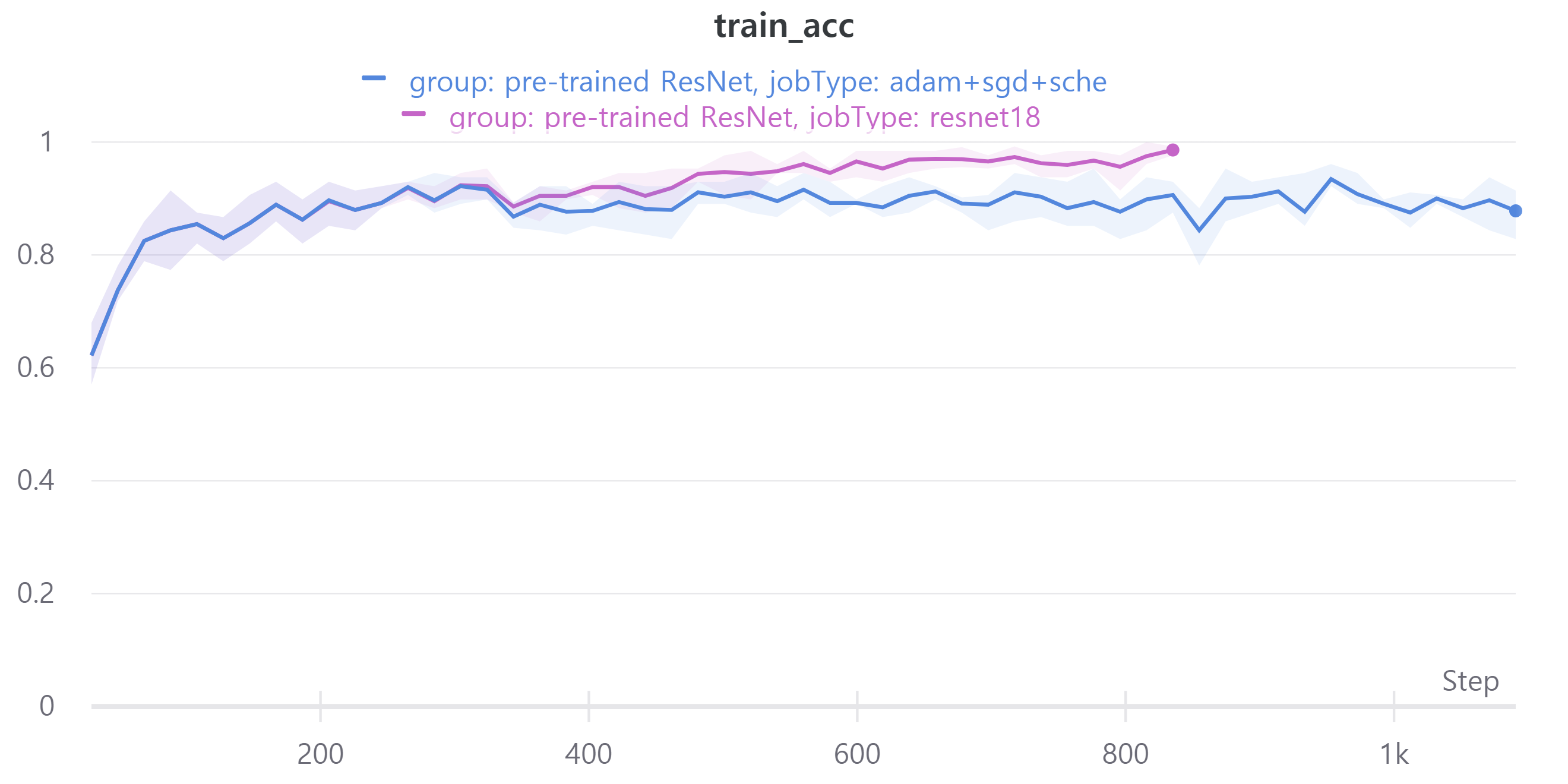
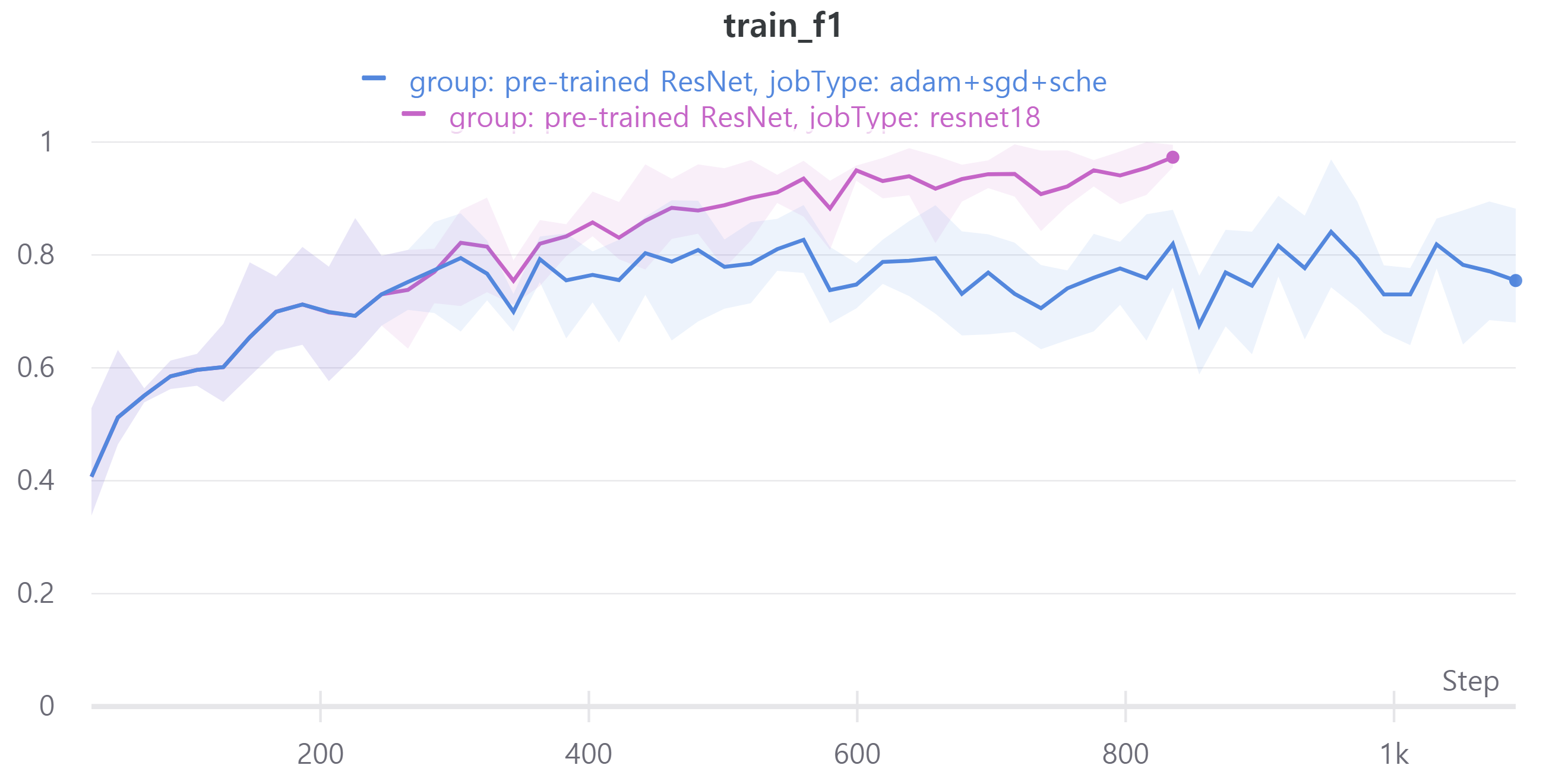
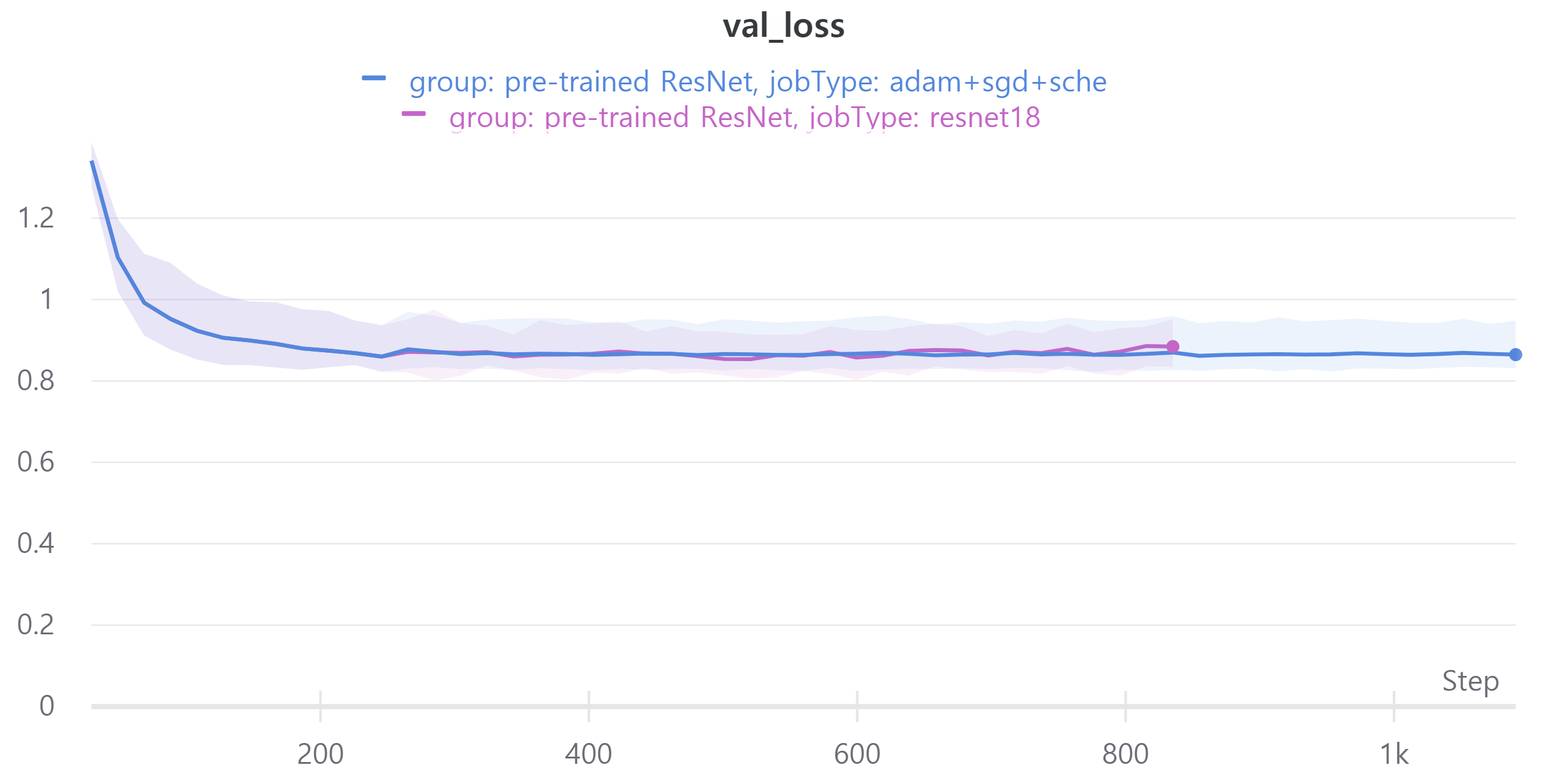
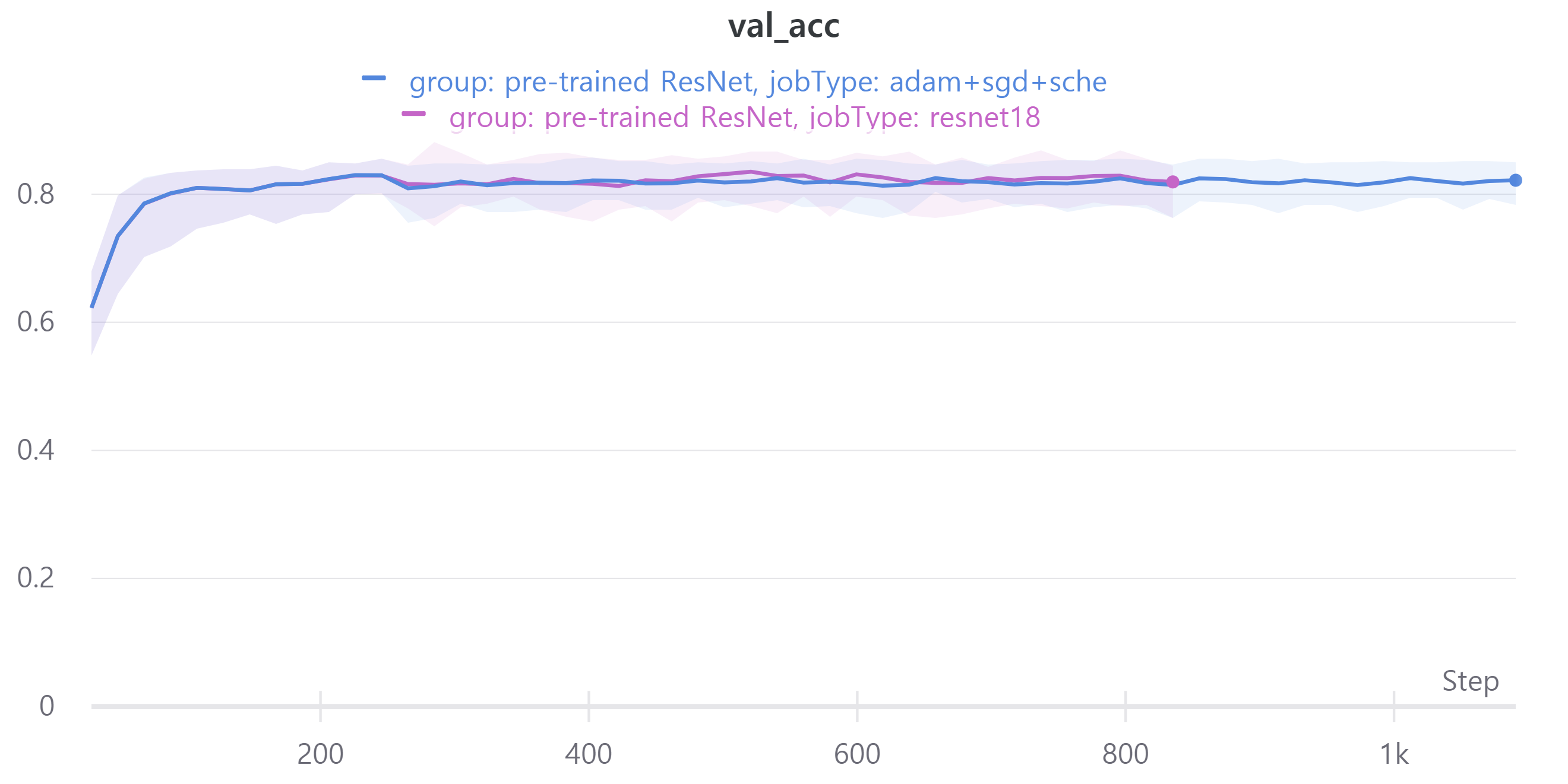
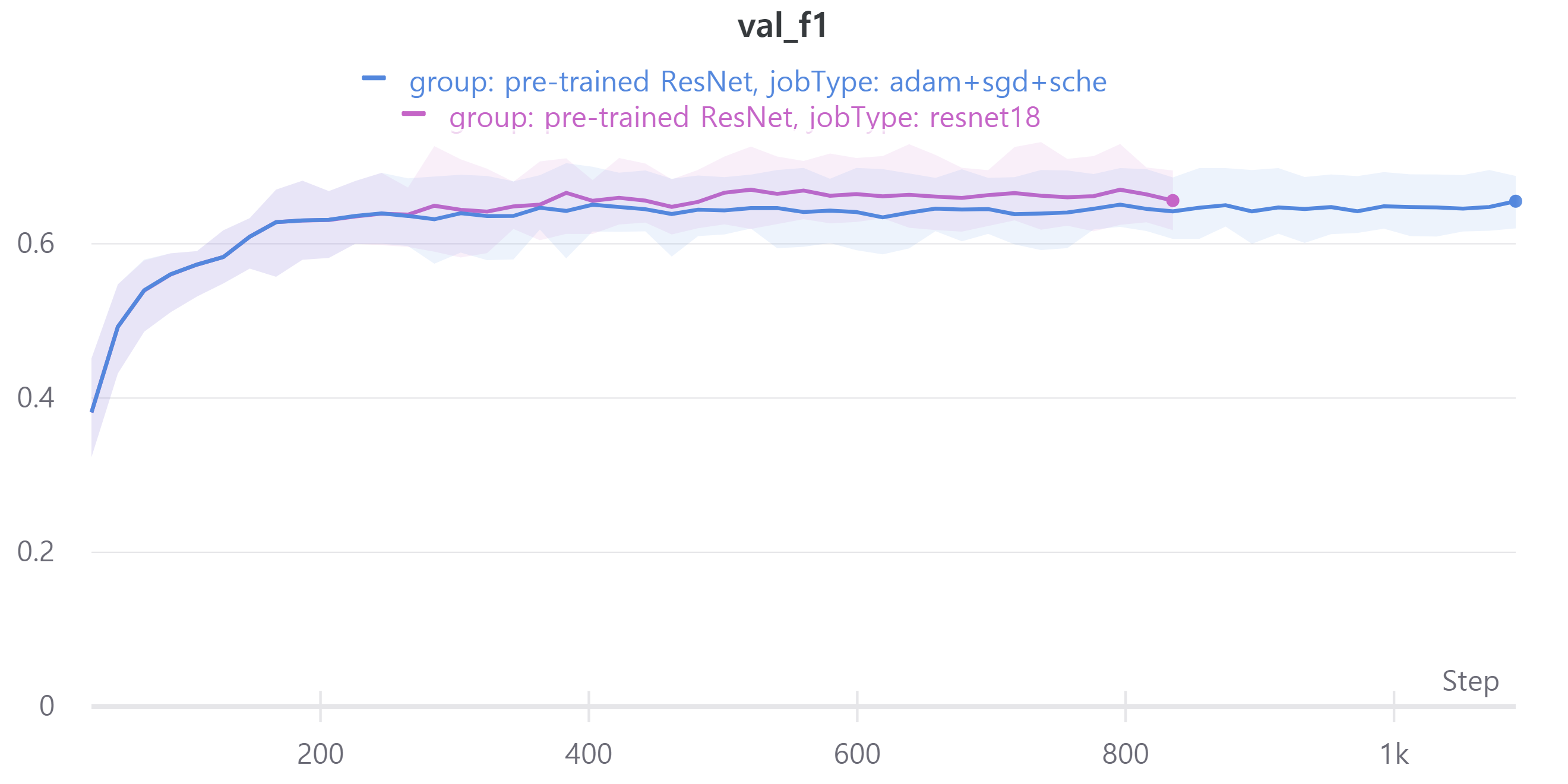
validation에 대한 성능은 비슷해서 신기했다.
즉 sgd는 일반화 성능에 영향을 준다.
그래서 오늘의 결론은 ResNet의 layer에 따라 성능 차이가 많이 나지 않아 가벼운 모델인 ResNet18을 앞으로 사용할 예정이다.
ResNet152도 있지만 학습하는데 오래 걸려서 생략했다.
To do
- mix-up
- 마스크 착용 데이터 학습