turing test
1950년 앨런 튜링에 의해 개발된 튜링 테스트는 인간의 것과 동등하거나 구별할 수 없는 지능적인 행동을 보여주는 기계의 능력에 대한 테스트다.
튜링은 인간 평가자가 인간과 같은 반응을 일으키도록 설계된 기계 사이의 자연 언어 대화를 판단할 것을 제안했다.
평가자는 대화의 두 파트너 중 한 명이 기계라는 것을 알고 모든 참가자는 서로 분리될 것이다.
대화는 컴퓨터 키보드와 화면과 같은 텍스트 전용 채널로 제한되어, 그 결과는 단어를 연설로 렌더링하는 기계의 능력에 좌우되지 않을 것이다.
평가자가 기계와 인간을 확실하게 구분할 수 없는 경우, 그 기계는 시험에 합격했다고 볼수있다.
시험 결과는 기계의 질문에 대한 정답을 제시하는 능력을 평가하는것이 아니라, 기계가 제시하는 답이 얼마나 인간다운 대답인지를 평가한다.1
fastText
이 부분은 이 논문을 참고하여 간단하게 작성하였다.
기존의 모델들은 서울, 서울역, 서울사람을 다른 단어로 본다.
만약 학습 데이터에 서울이 있고 테스트 데이터에 서울역, 서울사람이 있다면 이를 embedding하지 못한다.
방대한 단어 사전을 가지는 경우 빈도수가 낮은 단어들은 제대로 embedding되지 않을 것이다.
이 논문에서는 skip-gram에 기반한 새로운 방법을 제안한다.
각 단어를 n-gram으로 만들어 학습한다.
단어는 n-gram으로 된 단어들의 embedding의 합으로 표현된다.
(즉, subword를 embedding하여 그 합을 embedding으로 사용한다.)
학습 데이터에 없는 단어도 embedding을 구할 수 있다.
이전 모델과 차이점은 fastText는 subword를 사용한다.
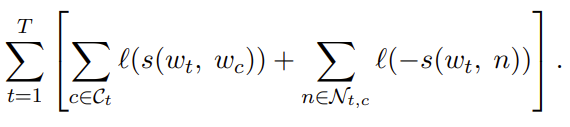
$s(w_t, w_c) = \bold{u}^T_{w_t}\bold{v}_{w_c}$ , $w_t$ 는 중심 단어이고 $w_c$ 는 context word이다.
이 모델은 중심 단어와 context word의 내적이 score function으로 정의된다.
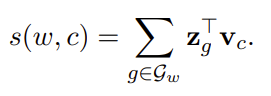
위 수식처럼 fastText는 중심단어 $w$ 의 n-gram 단어와 context word의 내적의 합으로 정의된다.
이때 $\mathcal{G}_w$ 는 $w$ 의 n-gram 단어와 $w$ 를 포함한다.
embedding measure
embedding이 잘 되었는지 확인하는 방법을 알아본다.
- wordsim353
similarity와 relatedness를 측정하기 위한 dataset이다.
사람들이 직접 두 단어가 얼마나 유사한지를 점수를 매겼다.
총 353개의 단어쌍에 대해 측정했다.
예를 들어 사랑 - 섹스의 유사도는 6.77, 호랑이 - 고양이는 7.35 - spearman`s correlation
통계에서 스피어먼 상관 계수는 두 변수 의 순위 사이의 통계적 의존성을 측정하는 비모수적인 척도이다.
이는 두 변수의 관계가 단조함수(單調函數,monotonic function)를 사용하여 얼마나 잘 설명될 수 있는지를 평가한다.2
여기서는 wordsim353 같은 인간이 매긴 유사도와 모델에 의해 얻은 유사도의 순위를 비교한다.
A 라는 단어와 유사한 단어들의 순위를 wordsim353와 모델에서 얻을 수 있고 이에 대해 상관 계수를 구하는 것이다. - analogy test
한 단어쌍 (A, B)가 주어질때 이를 보고 C에 대응하는 D를 찾는 test이다.
transformer limitation
transformer 모델의 한계점이 뭘까?
sequence의 길이 제곱에 비례하여 메모리와 연산량이 증가한다.
그래서 BERT의 경우 길이를 512으로 제한하며 긴 문서를 연산하기 힘들다.
이런 문제점을 longformer, linformer, Reformer 논문에서 개선하는 방법을 제시한다.