추천 시스템(recommendation system) 1
A recommender system, or a recommendation system (sometimes replacing ‘system’ with a synonym such as platform or engine), is a subclass of information filtering system that seeks to predict the “rating” or “preference” a user would give to an item.
추천 시스템은 “평점” 혹은 유저들이 아이템에 주는 “선호도”를 예측하는 information filtering system의 하위 클래스이다.
추천 시스템이 왜 필요할까?
One key reason why we need a recommender system in modern society is that people have too much options to use from due to the prevalence of Internet.
In the past, people used to shop in a physical store, in which the items available are limited.
nowadays, the Internet allows people to access abundant resources online. Although the amount of available information increased, a new problem arose as people had a hard time selecting the items they actually want to see.2
현대 사회에서 추천이 필요한 중요한 이유는 사람들은 인터넷 덕분에 많은 선택을 할 수 있기 때문이다.
과거에는, 물건 이용이 제한적인 실제 매장을 이용했다.
오늘날에는, 인터넷이 사람들에게 온라인으로 풍부한 정보에 접근하는 걸 가능하게 한다.
비록 이용할 수 있는 정보가 증가했지만, 사람들이 그들이 정말 보길 원하는 물건을 선택하는 시간하는데 어려움을 겪으면서 새로운 문제가 발생했다.
 3
3
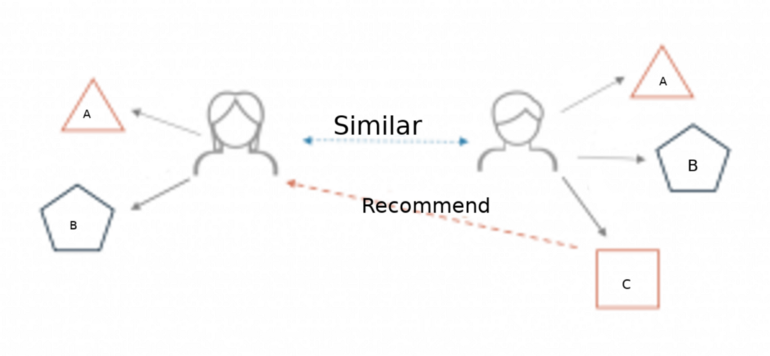
위 그림은 추천의 한 예이다.
우리는 graph를 배우고 있다.
여기서 정점은 유저와 아이템이며 종류가 다르다.
따라서 정점의 종류가 2개인 bipartite graph이다.
간선은 유저에서 아이템으로 향하는 directed graph이다.
만약 아이템에 평점을 매길 수 있다면 간선에 가중치가 있는 weighted graph가 된다.
그래서 graph 관점에서 추천은 미지의 간선을 예측 혹은 가중치 추정이다.
추천 시스템은 아래 그림과 같은 방법으로 나뉜다.
이 중 content-based filtering과 collaborative filtering을 살펴본다.

content-based filtering
filtering이라는 단어가 들어간 이유는 불필요하거나 중요하지 않은 정보를 제거하기 때문이다.
즉, content 기반으로 추천한다는 의미이다.
Content-based filtering methods are based on a description of the item and a profile of the user’s preferences.
These methods are best suited to situations where there is known data on an item (name, location, description, etc.), but not on the user.
Content-based recommenders treat recommendation as a user-specific classification problem and learn a classifier for the user’s likes and dislikes based on an item’s features.
In this system, keywords are used to describe the items and a user profile is built to indicate the type of item this user likes.
In other words, these algorithms try to recommend items that are similar to those that a user liked in the past, or is examining in the present.
content-based filtering 방법들은 아이템과 유저의 선호도에 기반한다.
이 방법들은 아이템에 알려진 데이터(이름, 위치, 설명 등)이 있고 유저에 대해서는 없는 상황에 가장 적합하다.
content-based 추천들은 추천을 유저별 분류 문제로 다루고 아이템의 특징들에 기반하여 유저들의 좋아요와 싫어요에 대해 classifier를 학습한다.
키워드들은 아이템을 묘사하는데 사용되고 유저 프로필은 이 유저가 좋아한 아이템의 타입을 가리키기 위해 만들어진다.
즉, 이 알고리즘들은 과거에 유저가 좋아했던 아이템들과 비슷한 것을 추천한다.
예를 들어, 동일한 장르의 영화, 동일한 감독의 영화 혹은 동일 배우가 출현한 영화를 추천하는 것이다.
그럼 추천 과정에 대해 좀 더 알아보자.
- 모든 아이템에 대해 특성이 담긴 벡터로 표현해야 된다.
- 먼저 유저가 어떤 아이템을 선호하는지 파악한다.
유저가 선호하는 아이템들의 특성을 추출한다.
유사도를 구하기 위해서 추출한 특성을 벡터로 나타낸다. - 모든 아이템 특성과 앞서 추출한 특성과 비교하여 가장 유사한 아이템을 추천한다.
앞서 추출한 특성 벡터와 아이템 특성 벡터와 유사도를 구한다.
가장 유사도가 높은 아이템을 추천한다.
여기서 유사도는 cosine similarity를 사용한다.
content-based filtering의 장점은 다음과 같다.
- 다른 유저의 기록이 필요하지 않다.
- 독특한 취향의 유저에게도 추천할 수 있다.
- 새 상품에 대해서도 추천할 수 있다.
- 추천 이유를 설명할 수 있다.
예를 들어, 로맨스 영화를 선호하기에 추천했다.
물론 단점도 존재한다.
- 상품에 대한 부가 정보가 없는 경우에는 사용할 수 없다.
- 구매 기록이 없는 사용자에게는 사용할 수 없다.
- 과적합(Overfitting)으로 지나치게 협소한 추천을 할 위험이 있다.
유저가 알고있는 범위 내에서 추천을 하게 된다.
즉, 추천에 신선함(novelty)가 떨어진다.
협업 필터링(collaborative filtering) 4

collaborative filtering(이하 CF)는 추천 방법 중 하나이다.
CF는 다음과 같은 가정을 하고 있다.
The underlying assumption of the collaborative filtering approach is that if a person A has the same opinion as a person B on an issue, A is more likely to have B’s opinion on a different issue than that of a randomly chosen person.
CF의 가정은 만약 A라는 사람이 어떤 상황에서 B라는 사람과 같은 의견을 가진다면, 다른 상황에서 A는 임의로 선택된 사람의 의견보다 B의 의견을 가질 가능성이 있다.
또한 CF는 다음과 같은 동기가 있다.
The motivation for collaborative filtering comes from the idea that people often get the best recommendations from someone with tastes similar to themselves.
Collaborative filtering encompasses techniques for matching people with similar interests and making recommendations on this basis.
CF의 동기는 사람들은 종종 그들과 비슷한 취향을 가진 사람으로부터 최고의 추천을 받는 다는 생각에서 왔다.
CF는 비슷한 취향을 가진 사람과 매칭하고 추천하기 위한 기술을 포함한다.
CF는 유저들의 활발한 참여와 유저들의 취향을 표현하기 위한 쉬운 방법과 비슷한 취향을 가진 사람들을 연결할 수 있는 알고리즘이 필요하다.
CF는 다음과 같은 과정을 가진다.
- 한 유저와 비슷한 취향의 유저들을 찾는다.
- 이 유저들이 선호한 아이템을 찾고 추천한다.
CF의 관건은 유사한 유저들을 어떻게 묶고 어떻게 가중치를 주는가 이다.
CF의 장단점은 다음과 같다.
- 상품에 대한 부가 정보가 없는 경우에도 사용할 수 있다.
- 충분한 수의 평점 데이터가 누적되어야 효과적이다.
- 새 상품, 새로운 사용자에 대한 추천이 불가능이다.
- 독특한 취향의 사용자에게 추천이 어렵다.
그럼 유사한 유저는 어떻게 구할까?
상관계수를 이용한다.
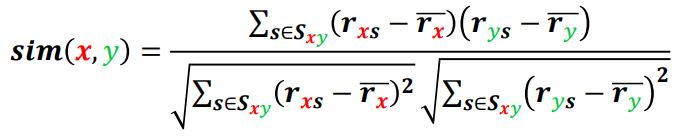
$sim(x, y)$: 유저 $x, y$ 의 유사도
$r_{xs}$: 유저 $x$ 가 아이템 $s$ 에 매긴 평점
$\bar{r_x}$: 유저 $x$ 가 매긴 모든 평점의 평균
$S_{xy}$: 유저 $x, y$ 가 평점을 공통적으로 매긴 상품들
community detection
나중에 추가…