mini-code
a = 256
print(a is 256) # True
b = 257
print(b is 257) # False
is는 주소값을 비교하고 ==는 값을 비교한다.
-5~256의 정수는 자주 사용한다고 생각하여 메모리에 미리 할당했다.
그래서 변수에 위 값을 할당하면 새롭게 값을 할당하는게 아니라 미리 할당되어 있던 주소를 가리킨다.
그래서 위 코드를 보면 print(a is 256) 은 True가 출력된다.
a는 메모리 어딘가 256이 저장된 주소를 가리킨다.
b에 257이 저장되며 print(b is 257)은 서로 가리키는 주소가 다르므로 False가 나온다.
1주차에 위 코드에 대해 배웠다.
하지만 정리를 안해놔서 여기다가 정리한다.
import sys
print(sys.getsizeof(0)) # 24
print(sys.getsizeof(1)) # 28
print(sys.getsizeof(2**30-1)) # 28
print(sys.getsizeof(2**30)) # 32
print(sys.getsizeof(2**60-1)) # 32
print(sys.getsizeof(2**60)) # 36
print(sys.getsizeof(2**90)) # 40, 30마다 4byte 증가
sys.getsizeof는 object의 byte size를 반환한다.
0을 저장하는데 무려 24byte가 필요하다는 사실에 충격을 받았다.
int는 4byte로 표현하고 unsigned의 경우 0 ~ $2^{32}-1$, signed의 경우 $-2^{31}$ ~ $2^{31}-1$ 를 표현할 수 있다.
그럼 24byte는 무려 $2^{96}-1$ 까지 표현할 수 있다.
이렇게 비효율적인 이유는 python에서는 모든 것이 객체이고 int 역시 객체이다.
또 하나의 충격적인 것은 python에는 integer에 대해 overflow가 없다.
즉, 어떤 정수라도 표현할 수 있다.
fixed-precision을 사용하지 않고 arbitrary-precision을 사용한다.
이로 인해 표현의 제약이 없고 대신에 많은 memory를 사용한다.
솔직히 더 자세한 내용은 모르겠다.
이 부분은 이 글을 보고 작성했다.
import dis
def add(a, b):
c = a + b
return c
r = add(10, 20)
print(r, add.__code__.co_varnames) # (30, ("a", "b", "c"))
dis.dis(add)
"""
3 0 LOAD_FAST 0 (a)
2 LOAD_FAST 1 (b)
4 BINARY_ADD
6 STORE_FAST 2 (c)
4 8 LOAD_FAST 2 (c)
10 RETURN_VALUE
"""
import dis
def add(a, b):
return a + b
r = add(10, 20)
print(r, add.__code__.co_varnames) # (30, ("a", "b"))
dis.dis(add)
"""
30 ('a', 'b')
2 0 LOAD_FAST 0 (a)
2 LOAD_FAST 1 (b)
4 BINARY_ADD
6 RETURN_VALUE
"""
dis module은 built-in module이며 CPython bytecode를 disassemble하여 분석을 해준다.
어떤 함수의 실행과정을 분석하고 싶다면 이 module을 이용하면 된다.
두 코드의 차이점은 함수 내부에 지역변수를 할당여부이다.
print(4 != 0 not in [1, 2, 3]) # True
print((4 != 0) not in [1, 2, 3]) # False
print(4 != 0 not in [0, 1, 2, 3]) # False
print((4 != 0) not in [0, 1, 2, 3]) # False
print(4 != 0 not in [1, 2, 3])는 사실 4 != 0 and 0 not in [1, 2, 3]과 같다.
그래서 and를 기준으로 4 != 0과 0 not in [1, 2, 3] 각각 계산하고 and를 계산한다.
위 코드의 실행은 stack을 이용하는 것 같은데 정확히 모르겠다……
decision making
연역적 추론(deductive reasoning)은 논리학 용어로, 이미 알고 있는 판단을 근거로 새로운 판단을 유도하는 추론이다.
여기서 이미 알고 있는 판단은 전제, 새로운 판단은 결론이다.
진리가 될 수 있는 가능성을 따지는 귀납 추론과는 달리, 명제들 간의 관계와 논리적 타당성을 따진다.
즉, 연역 추론으로는 전제들로부터 절대적인 필연성을 가진 결론을 이끌어 낼 수 있다.1
전제에 따라 같은 명제라도 다른 결과를 얻을 수 있다.
예를 들어 1+1은 2진법으로 1+1=102, 10진법으로 1+1=2라는 결과를 얻는다.
의사결정을 할 때 어떤 전제를 가지고 하는지 잘 확인해야 된다.
전제가 잘못되면 결과도 잘못되기 때문이다.
귀납 추론(induction) 또는 귀납법은 개별적인 특수한 사실이나 현상에서 그러한 사례들이 포함되는 일반적인 결론을 이끌어내는 추론 형식의 추리 방법이다.
곧 귀납은 개개의 구체적인 사실이나 현상에 대한 관찰로서 얻어진 인식을 그 유(類) 전체에 대한 일반적인 인식으로 이끌어가는 절차이며, 인간의 다양한 경험, 실천, 실험 등의 결과를 일반화하는 사고 방식이다.
논리학에서 있어서 연역법과는 달리 사실적 지식을 확장해 준다는 특징이 있지만, 전제가 결론의 필연성을 논리적으로 확립해 주지 못한다는 한계가 있다.2
위 정의는 나에겐 너무 어렵다.
귀납법은 관찰 혹은 경험으로 일반화하는 추론이라 생각한다.
만약 내가 관찰한 까마귀의 색이 모두 검정색이라면 귀납법에 의해 모든 까마귀의 색은 검정색이다 라고 할 수 있다.
이런 추론법은 관찰 결과에 따라 달라진다.
의사결정이라는 단어는 machine learning에서 핵심이다.
가령 세탁기, 청소기 등 사람 대신에 기계가 세탁, 청소를 대신 해준다.
machine learning은 결정기이다.
사람 대신에 결정을 해준다.
우리는 결정기를 만드는 공부를 하고 있다.
결정기의 성능이 좋아짐에 따라 기계가 대신 해주는 영역이 늘었다.
추천시스템은 결정기의 성능이 약간 부족해도 적용 가능했다.
성능이 중요한 영역, 예를 들어 챗봇, 자율주행, 금융,에는 적용하기 힘들었지만 기술의 발전으로 사람이 내리던 결정을 기계가 대신 해주는 시대가 왔다.
lightweight model
경량화는 불필요한 것을 제거하고 필요한 것만 남기는 걸 말한다.
소형화는 크기 혹은 규모를 줄이는 것을 말한다.
우리가 하는 것은 모델의 경량화이며 모델의 크기를 줄이는 게 아니라 불필요한 부분을 제거함으로써 모델을 가볍게 만드는 것이다.
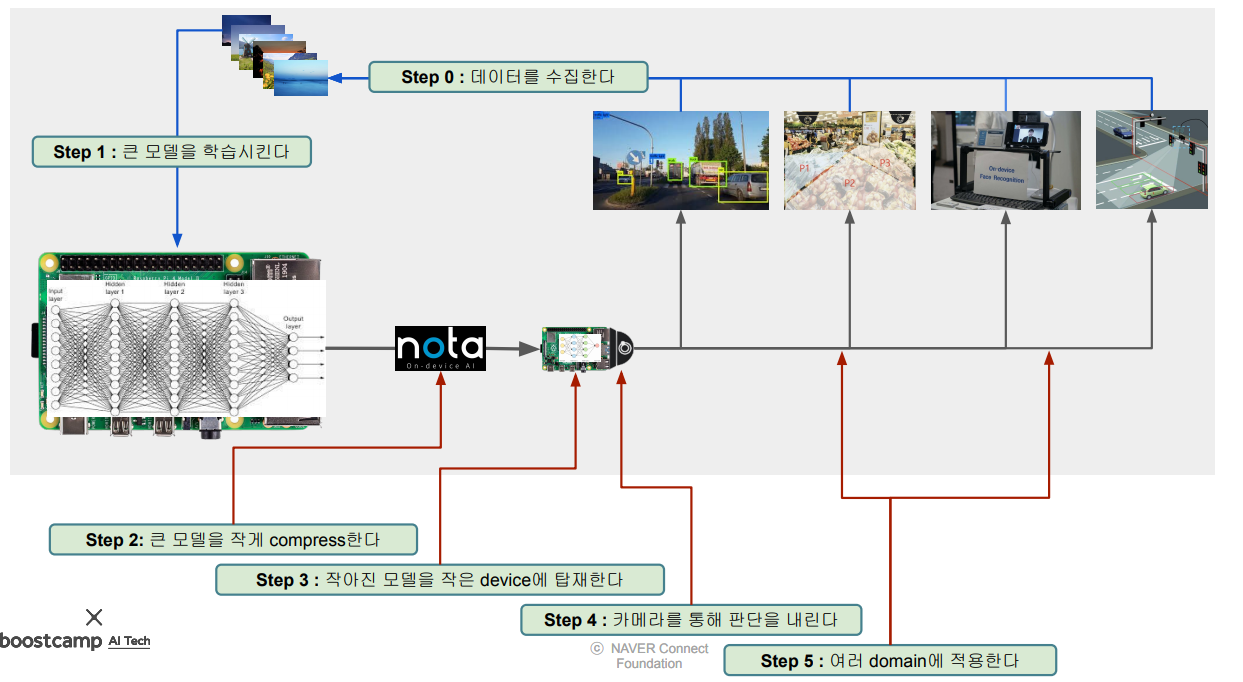
machine learning을 실생활에 적용하는 과정을 살펴보자.
- 데이터를 수집한다.
- 모델을 학습한다.
- device에 탑재할 수 있을 정도로 모델을 경량화시킨다.
- 모델을 device에 탑재한다.
- device의 센서를 통해 판단한다.
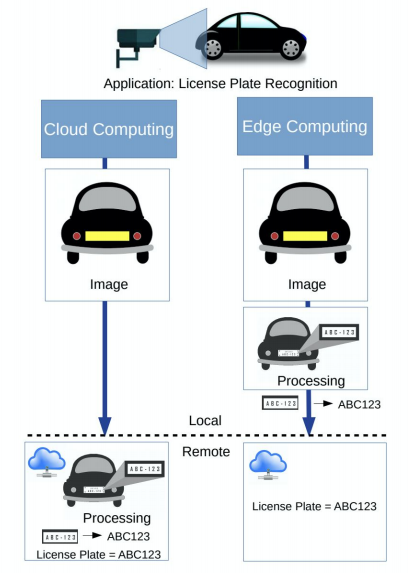 3
3
만약 경량화를 하지 않는다면 센서에서 수집한 데이터를 서버에 보내고 결과를 다시 받는 과정이 필요하다.
이 과정은 network I/O가 발생하며 의사결정을 하는데 시간이 많이 걸린다.
경량화를 했다면 실시간으로 수집한 데이터에 대해 device가 판단하여 어떠한 행동을 할 수 있을 것이다.
단점은 성능이 좋지 않을 수 있다.